一个比赛和几个经典
计算机视觉比赛ILSVRC(ImageNet Large Scale Visual Recognition Challenge)基于ImageNet图像数据库的国际计算机视觉识别竞赛。 包括目标定位、目标检测、场景分类、场景分析、图片分类等项目。
比赛数据集大概拥有120万张图片,1000类的标注。
比赛采用top-5和top-1分类错误率。

ILSVRC采用的ImageNet(发起人为李飞飞)的子数据集 , ImageNet拥有1500万标注过的高清图片,22000类,100万张标注了图片中主要物体的定位边框。
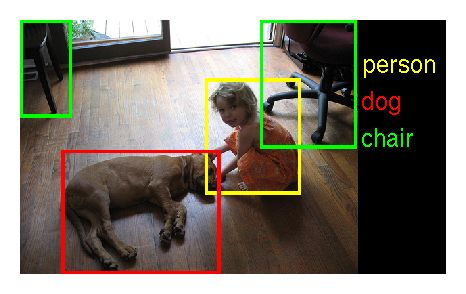
ImageNet下载了互联网上近10亿张图片,用亚马逊的土耳其机器人平台实现众包的标注过程,吸引了167个国家5万名工作者筛选标注。
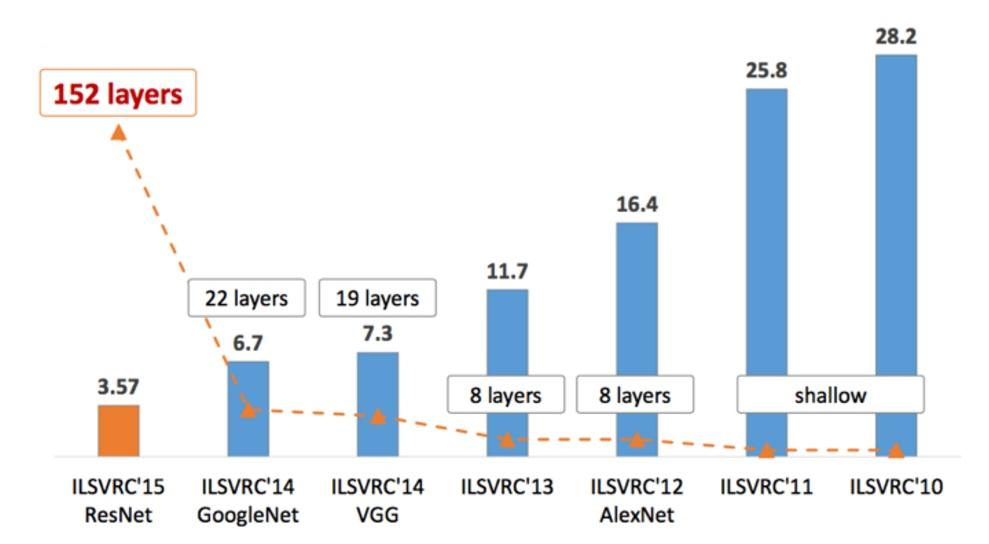
ILSVRC过去几年的比赛结果
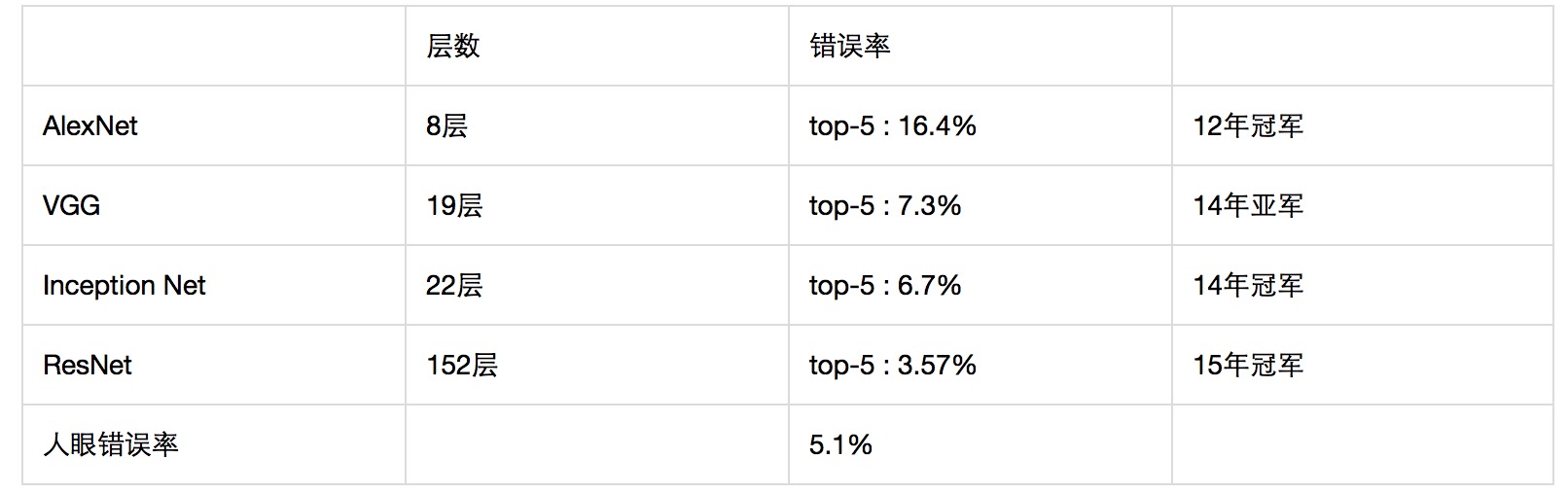
历届ILSVRC比赛代表性模型成绩及其深度
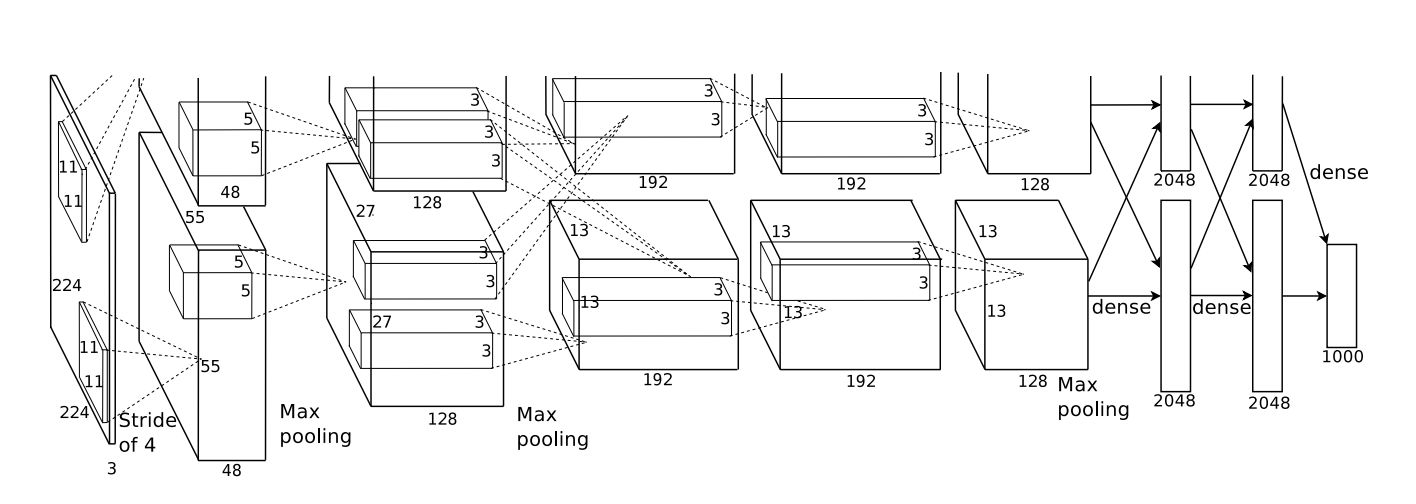
AlexNet
2012年Hiton的学生 Alex 提出了AlexNet , 将LeNet的思想发扬光大。
网络包含了6亿3000万个链接, 6000万个参数和65万个神经元,5个卷积层+3个全连接层。
错误率达到了16.4% (同年第二名26.2%),确立了深度学习在计算机视觉的统治地位。
AlexNet创新点:
- 引用ReLU作为激活函数,替代了Sigmoid ,解决了梯度弥散问题。
- 引入Droput 随机忽略一部分神经元,避免过拟合。
- 引入重叠最大池化,替换了平均池化,避免了模糊化效果。
- 提出了LRN 层,对局部神经元的活动创建竞争机制。
- CUDA加速
- 数据增强,用截取、水平翻转、添加噪声增大数据量提高泛华能力。
VGG
VGGNet 由牛津大学计算机视觉组和 google deepMind 合作开发。
VGG比赛的时候使用VGG-16 ,错误率7.3%(同年冠军6.7%), 随后采用VGG-19 可以达到6.8% 。
VGGNet 在训练的时候用了4块GTX GPU ,每个网络耗费2-3周。
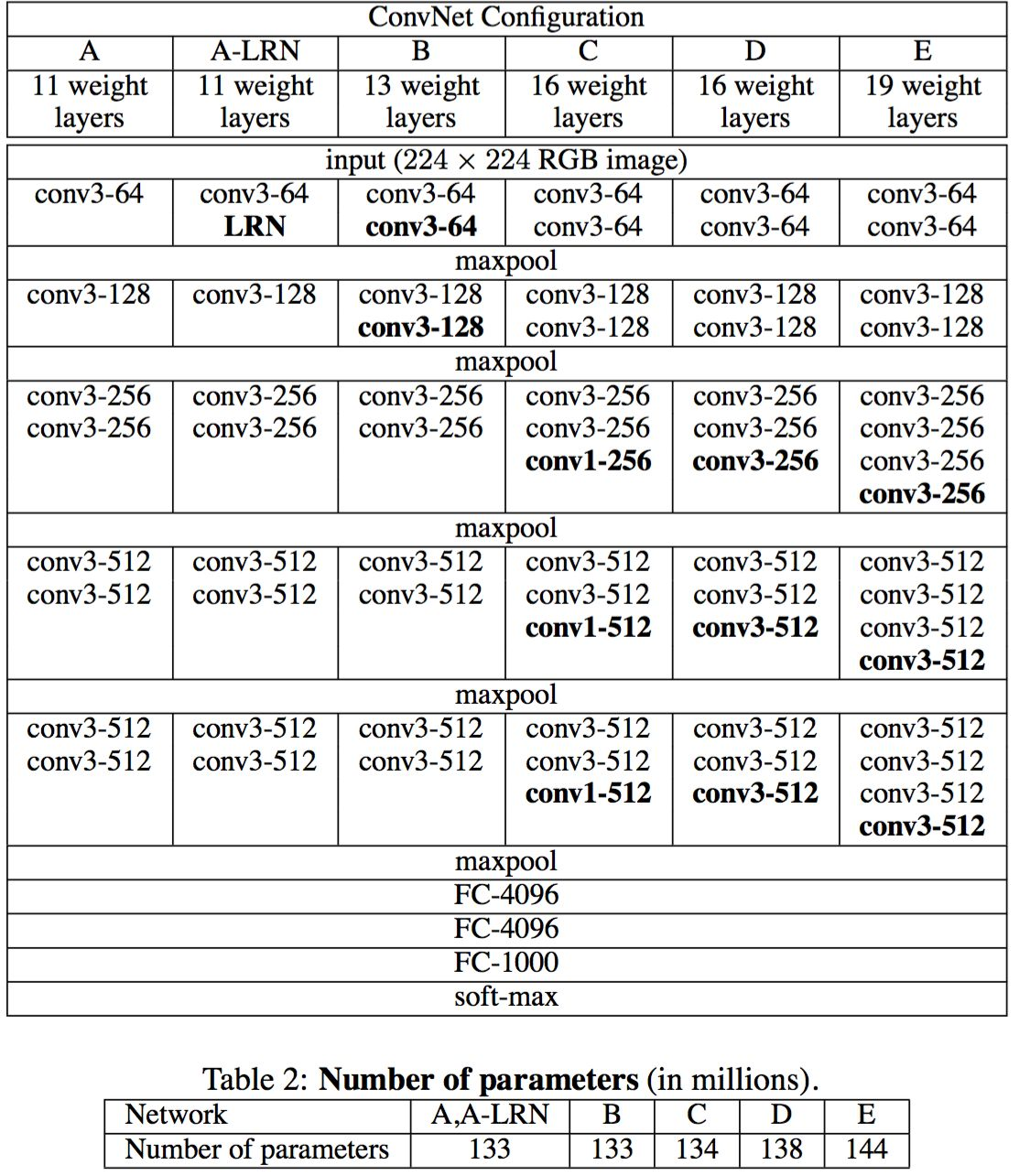
VGG创新点:
- 发现 LRN 层作用不大
- 越深网络效果越好
- 1x1卷积也是有效的,大的卷积核可以学到更大的空间特征。
- 卷积串联
eg: 两个3x3 相当于一个5x5 ,同时还多了更多的线性变换。
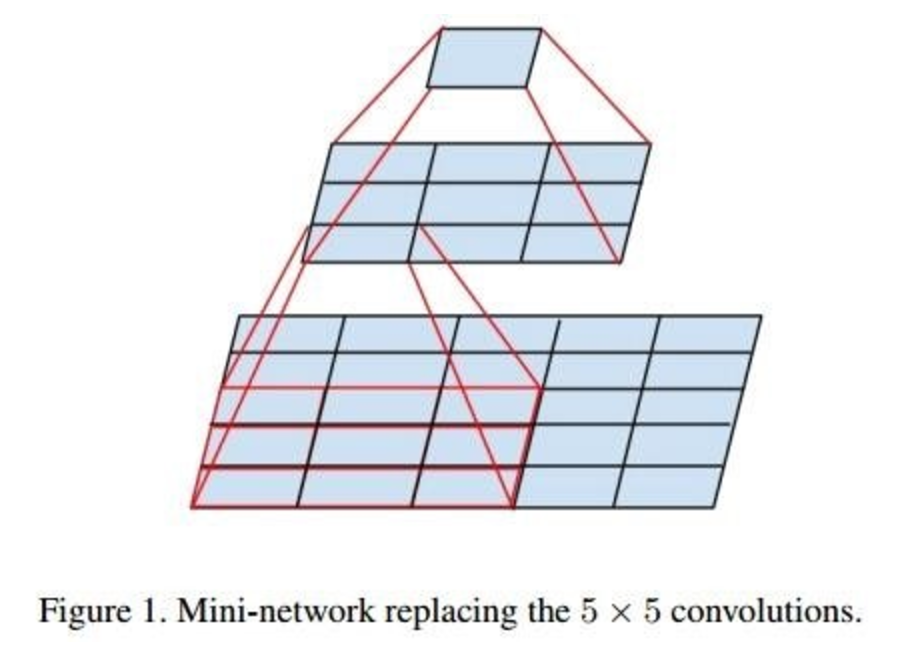
Google Inception Net
2014年冠军,top-5错误率6.67% (AlexNet : 16.4%) , 参数量500万(AlexNet:6000万)。
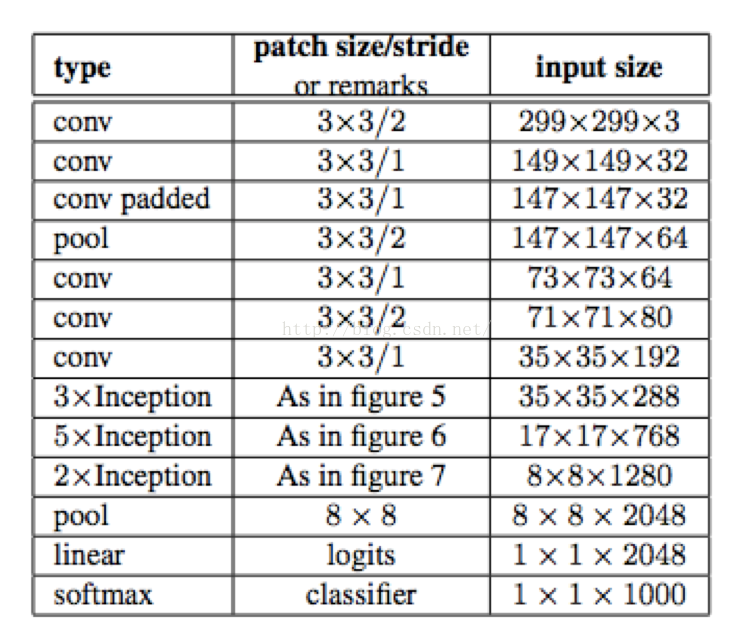
核心点 :NIN ( Network in Network ) 抽取不同程度的特征,既有简单的抽象也有更复杂的抽象
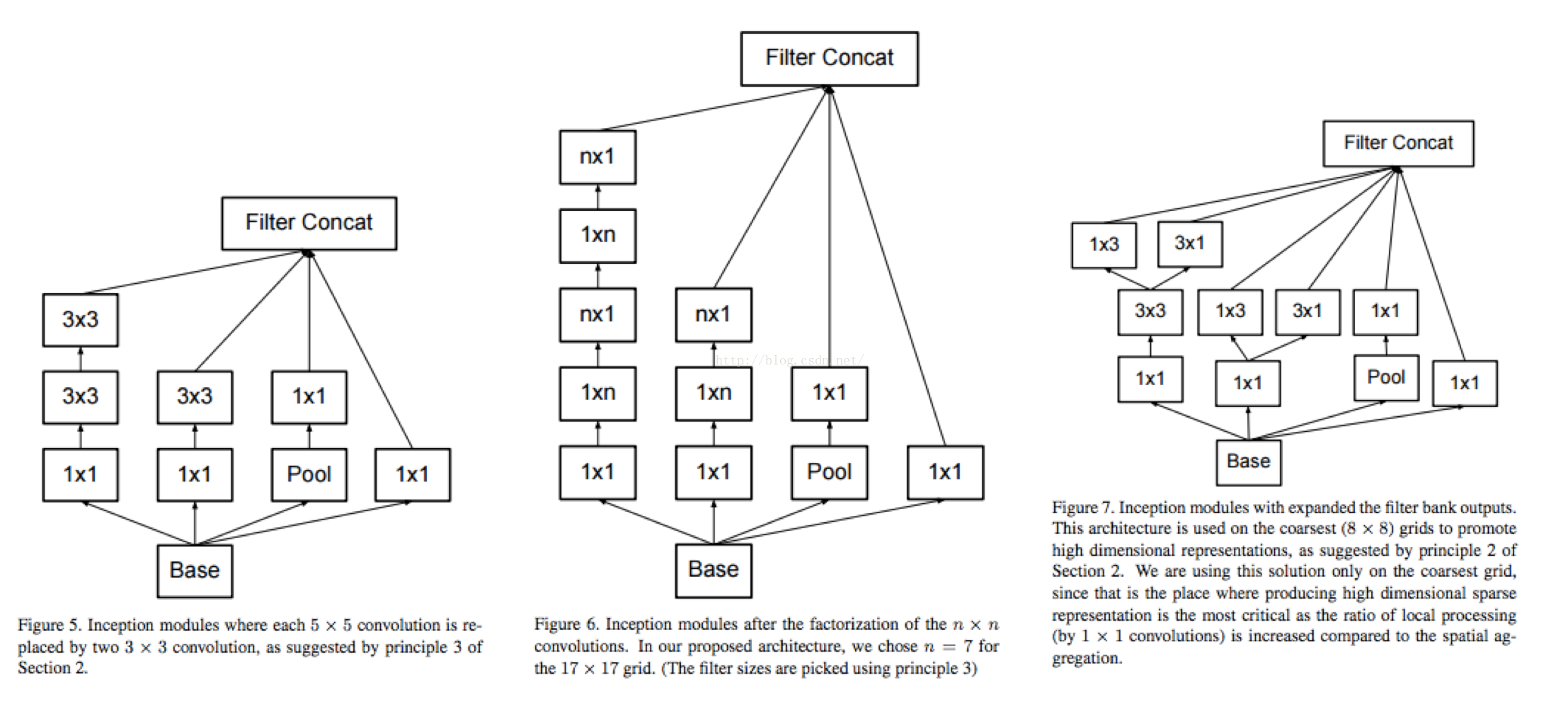
Google Inception Net 创新点:
- 同样去除了LRN
- Inception Module 用多个分支提取不同抽象程度的高阶特征,可以丰富表达能力。
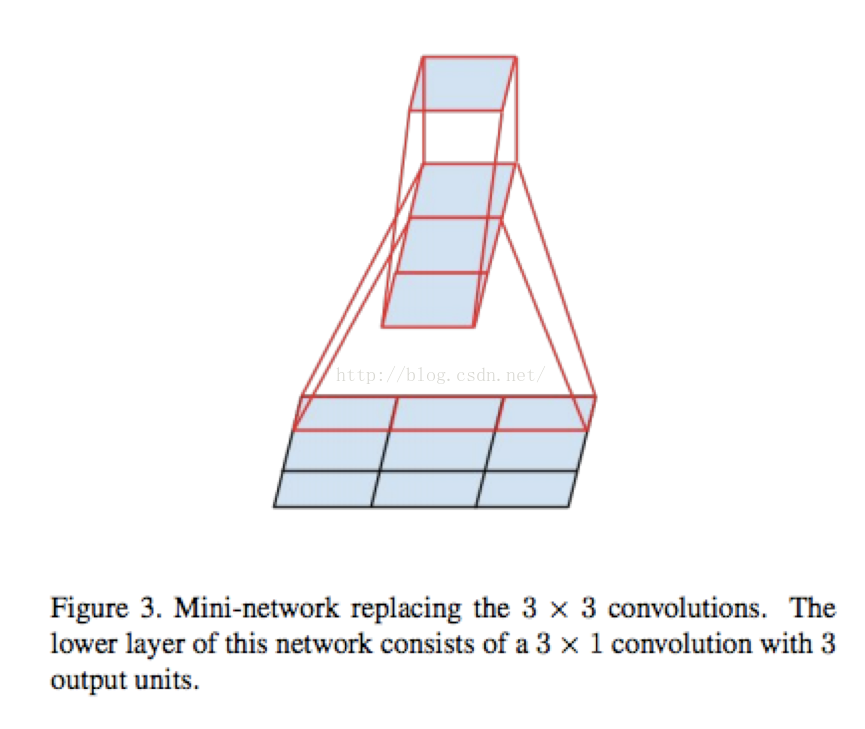
- 对卷积串联做的更彻底,引入了Factorization into small convolutions , 降低参数量,减小过拟合,增加非线性能力。
3x3 的卷积拆成 1x3 和 3x1的卷积串联。
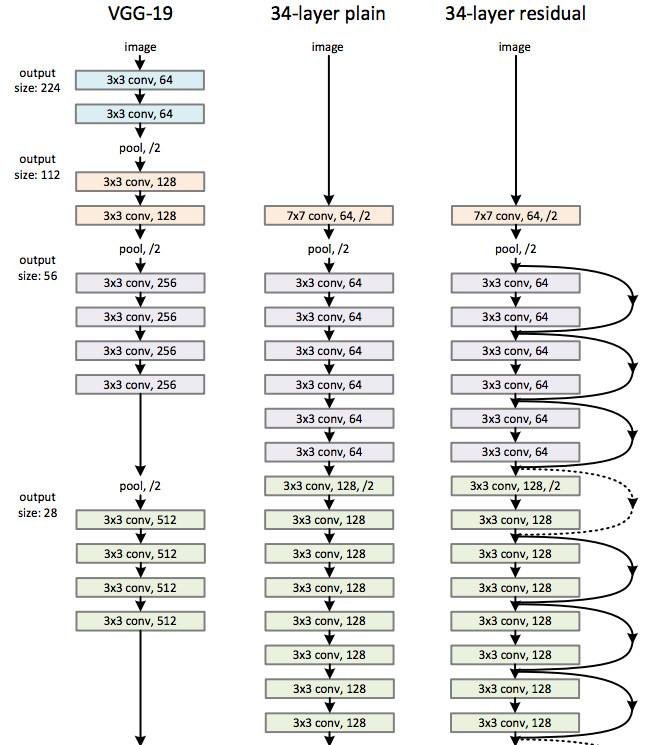
ResNet
由微软研究员Kaiming He 提出,错误率达到了3.57% , 152层神经网络。
主要的思想是:允许保留一定比例的原始输入信息传输到后面去。
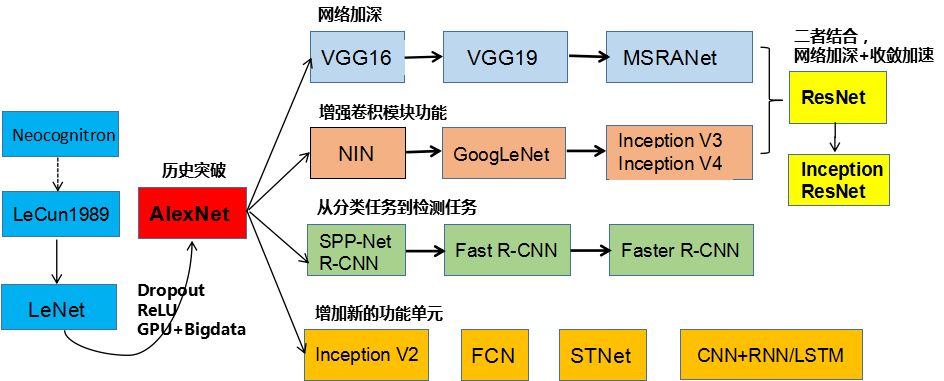
卷积神经网络发展分为两类,一类是网络结构上的调整,另一类是网络深度的增加
二、Tensorflow
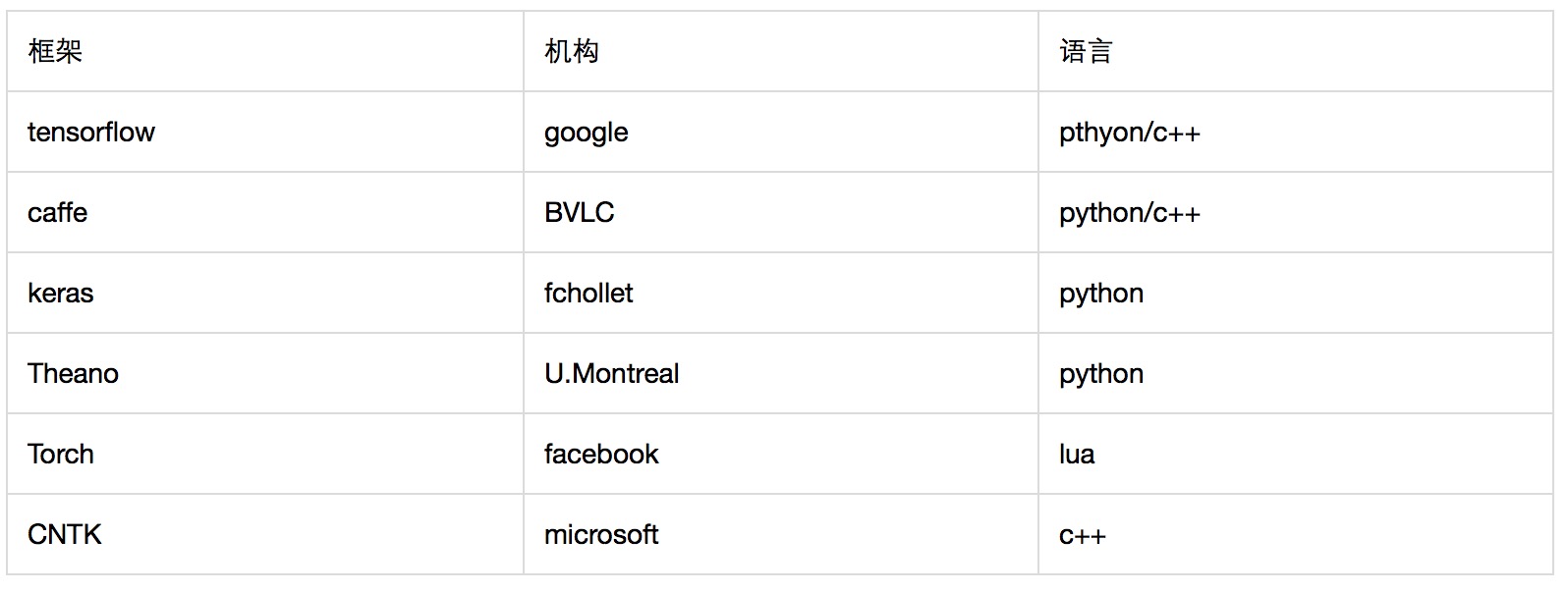
2.1 常用的深度学习框架
2.2 Tensorflow 初窥
2015年11月9日,Google发布人工智能系统TensorFlow并宣布开源。
1.张量(Tensor)
任意维度的数据,一维、二维、三维、四维等数据统称为张量。
在计算图的边中流动(flow)的数据被称为张量,故名tensorflow。
2.图(Graph)
图描述了计算的过程,也负责维护和更新状态。
3.计算节点(op)
机器学习算法被表达成图,图中的节点是一种运算操作(operation)。
4.会话(Session)
用户使用tensorFlow时的交互式接口。会话将图的op分发到诸如CPU或GPU之类的设备上执行。
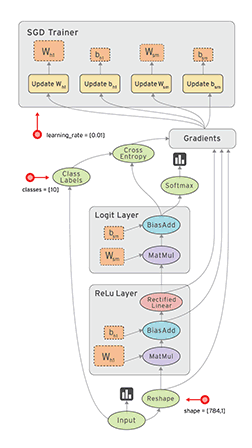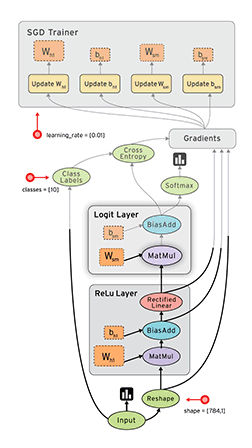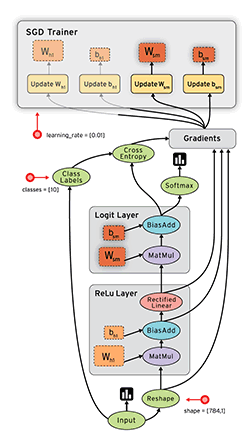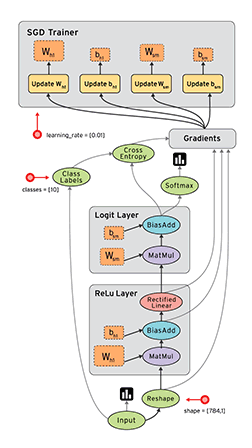
2.3 计算图示例
y=Relu(Wx+b)
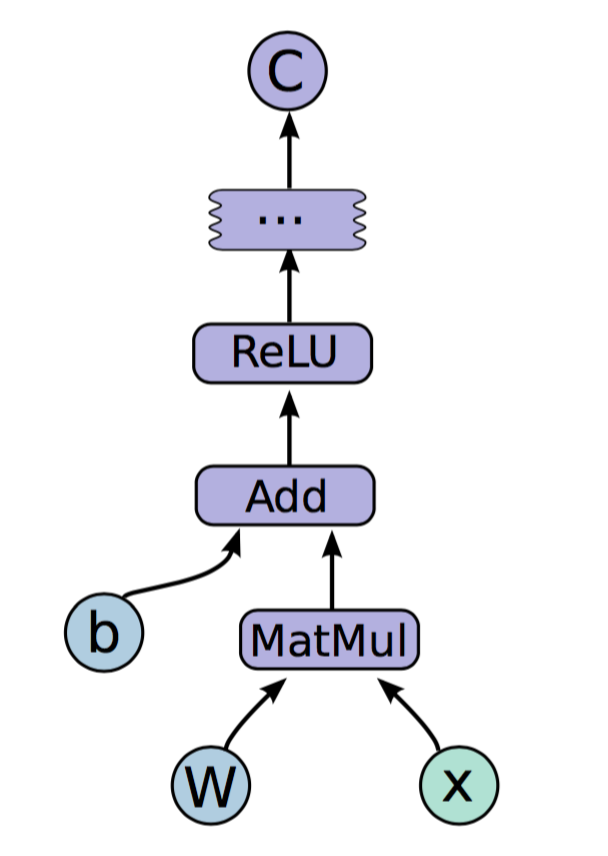
x= tf.placeholder(tf.float32, [None,784])
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
relu = tf.nn.relu(tf.matmul(x,W)+b)
sess = tf.InteractiveSession()// 建立交互式会话
tf.initialize_all_variables().run()//所有变量初始化
placeholder 与 variable
Variable : 声明时,必须提供初始值 , 一般用于模型的权重(weights)或者偏执值(bias)
placeholder : 不必指定初始值,运行时通过 Session.run 的函数参数指定 , 一般用来表达样本
2.4 Tensorflow 架构
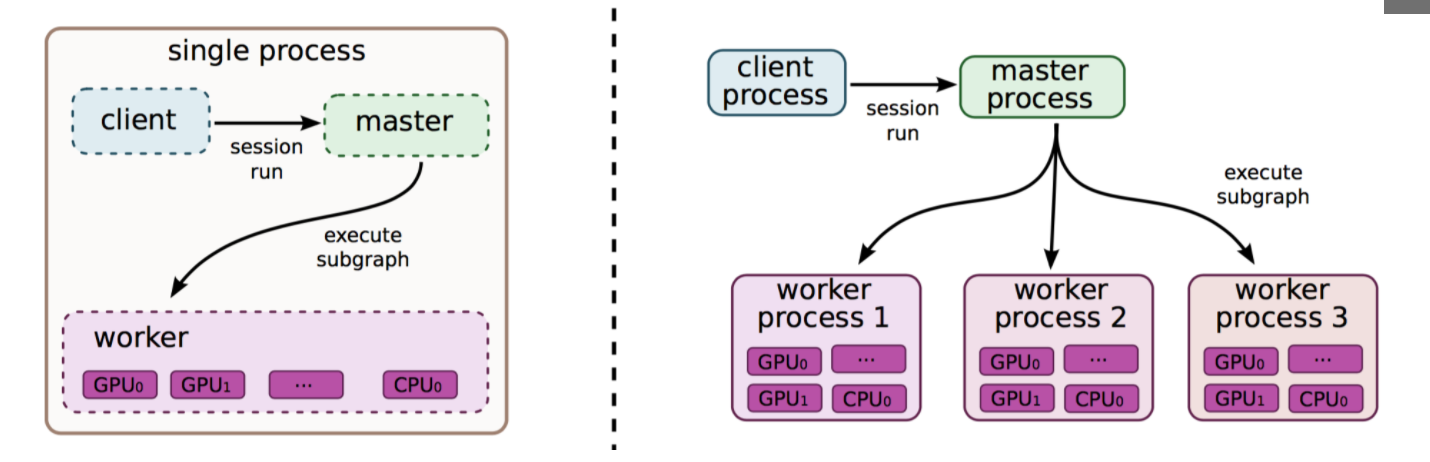
1、单机模式
(1)client , master , worker全部在一套机器上的同一个进程中。
(2)每一个worker可以管理多个设备。
(3)构建好图后,使用拓扑算法来决定执行哪一个节点。(做法是:对每个节点使用一个计数,值表示所依赖的未完成的节点数目,当一个节点的运算完成时,将依赖该节点的所有节点的计数减一。如果节点的计数为0,将其放入准备队列待执行)
2、分布式模式
(1)决定运算在哪个设备上运行
方法一: 贪心策略
首先计算一个代价模型,估算每一个节点的输入、输出tensor的大小,以及所需的计算时间。
模拟整个计算图,当遇到一个计算节点,把所有能执行这个节点的设备都测一遍
综合估算时间,传输时间选择和一个时间最小的设备。
方法二: 直接指定谁执行什么
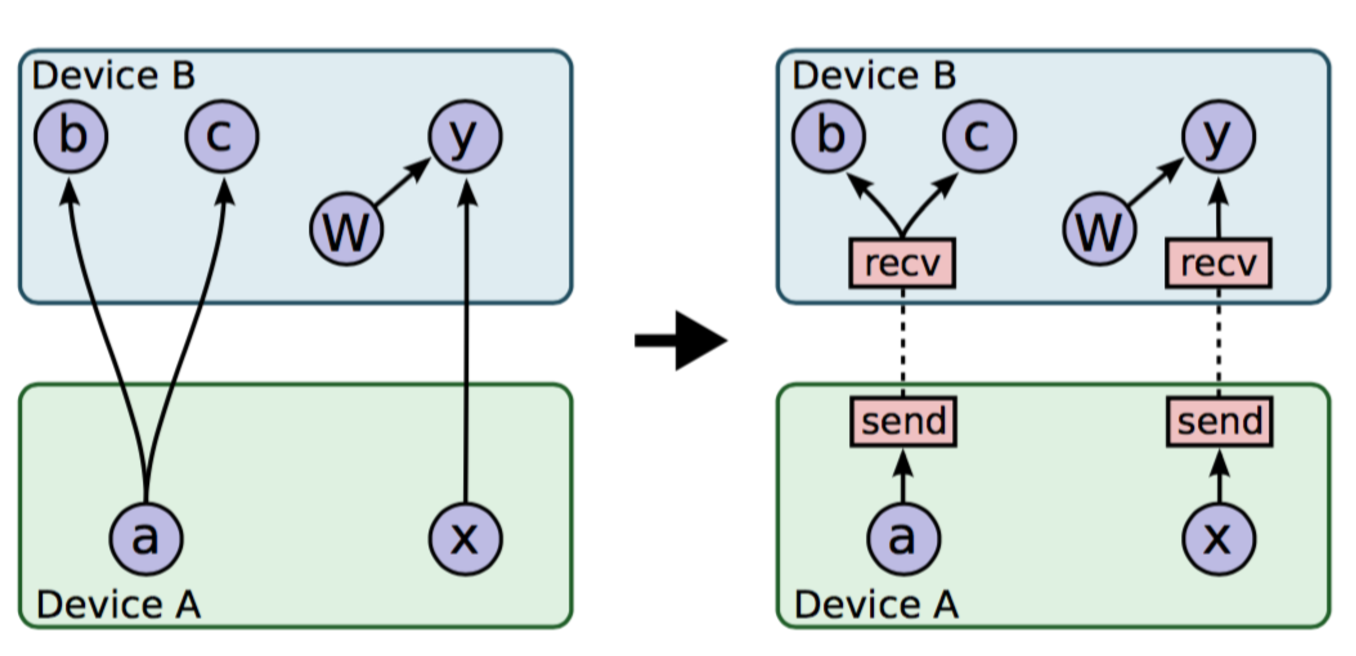
(2)管理设备之间的数据传递
添加Send和Recv节点,通过Send和Recv之间进行通信来达到op之间通信。
2.5 Tensorflow扩展性
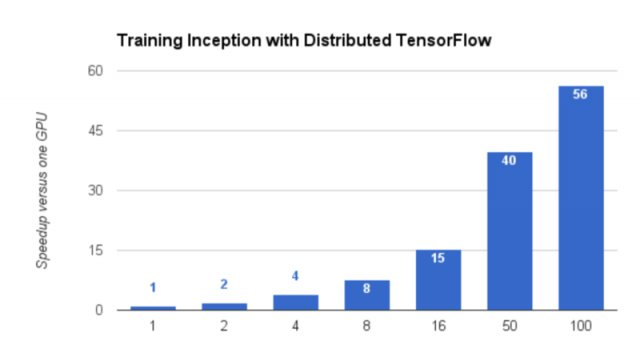
当GPU小于16的时候,性能基本没有损耗。
50块GPU的时候获得80%的效率, 也就是40倍单GPU的提速。
100块的时候得到56倍提速。
2.6 三种不同的加速神经网络训练的并行计算模式
(1)数据并行
分割数据,共享权重,合并梯度,同步/异步。
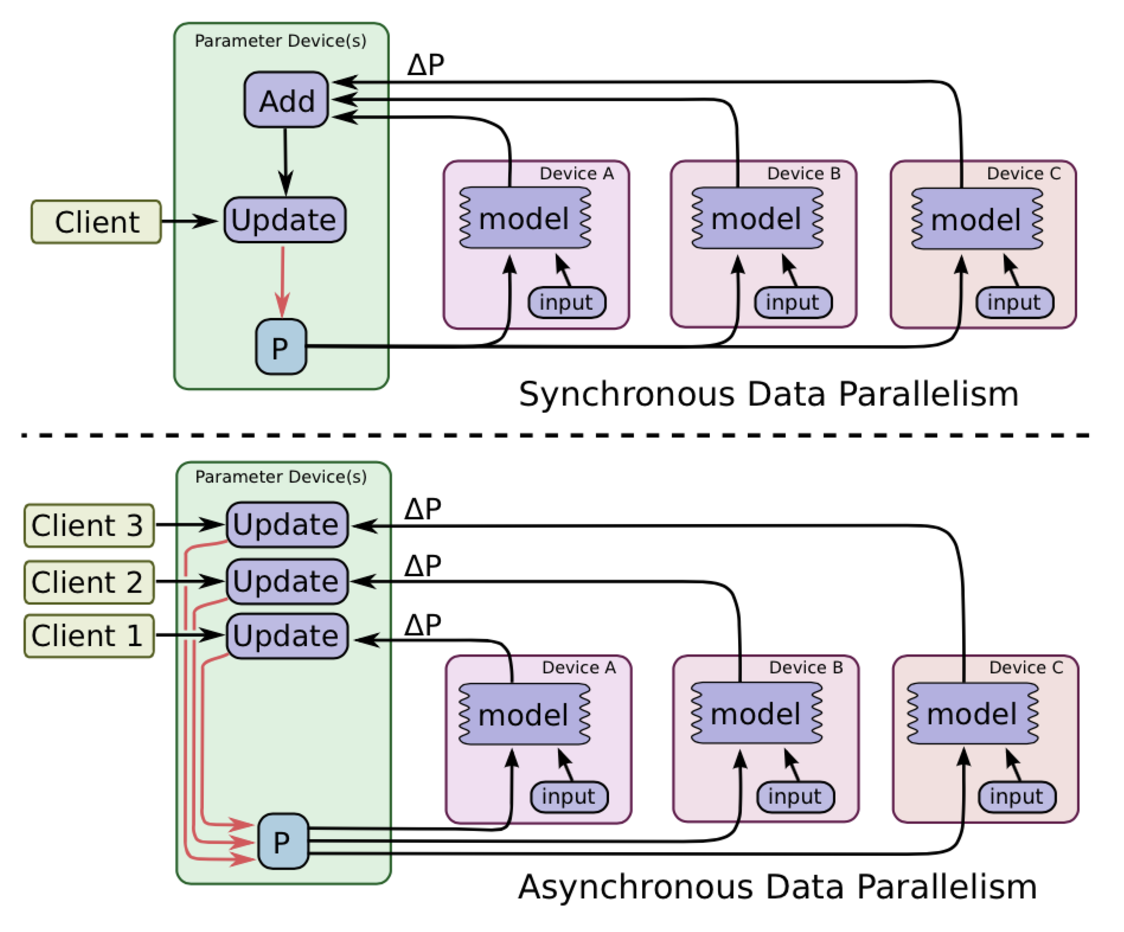
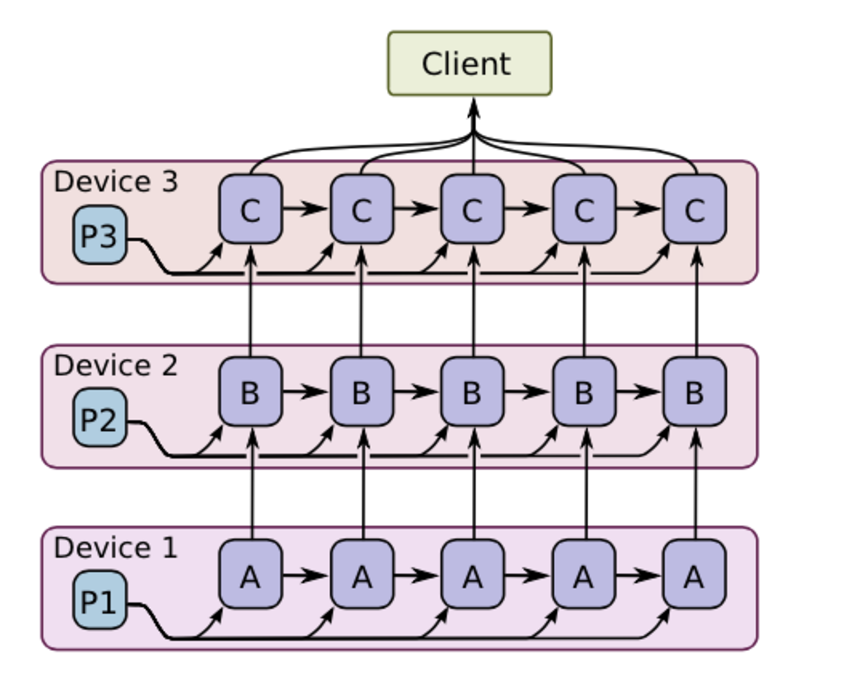
(2)模型并行
让模型的不同部分执行在不同的设备上。为了充分利用同一台设备的计算能力,TF会尽量让相邻的计算在同一台设备上,这样可以节省网 络开销。
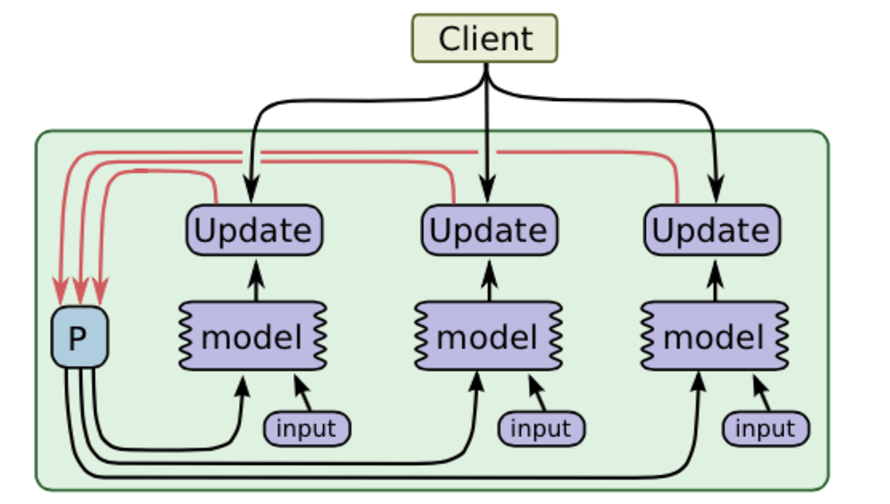
(3)流水线并行
和异步并行很像,但是是同一个硬件设备上实现并行,将计算做成流水线。
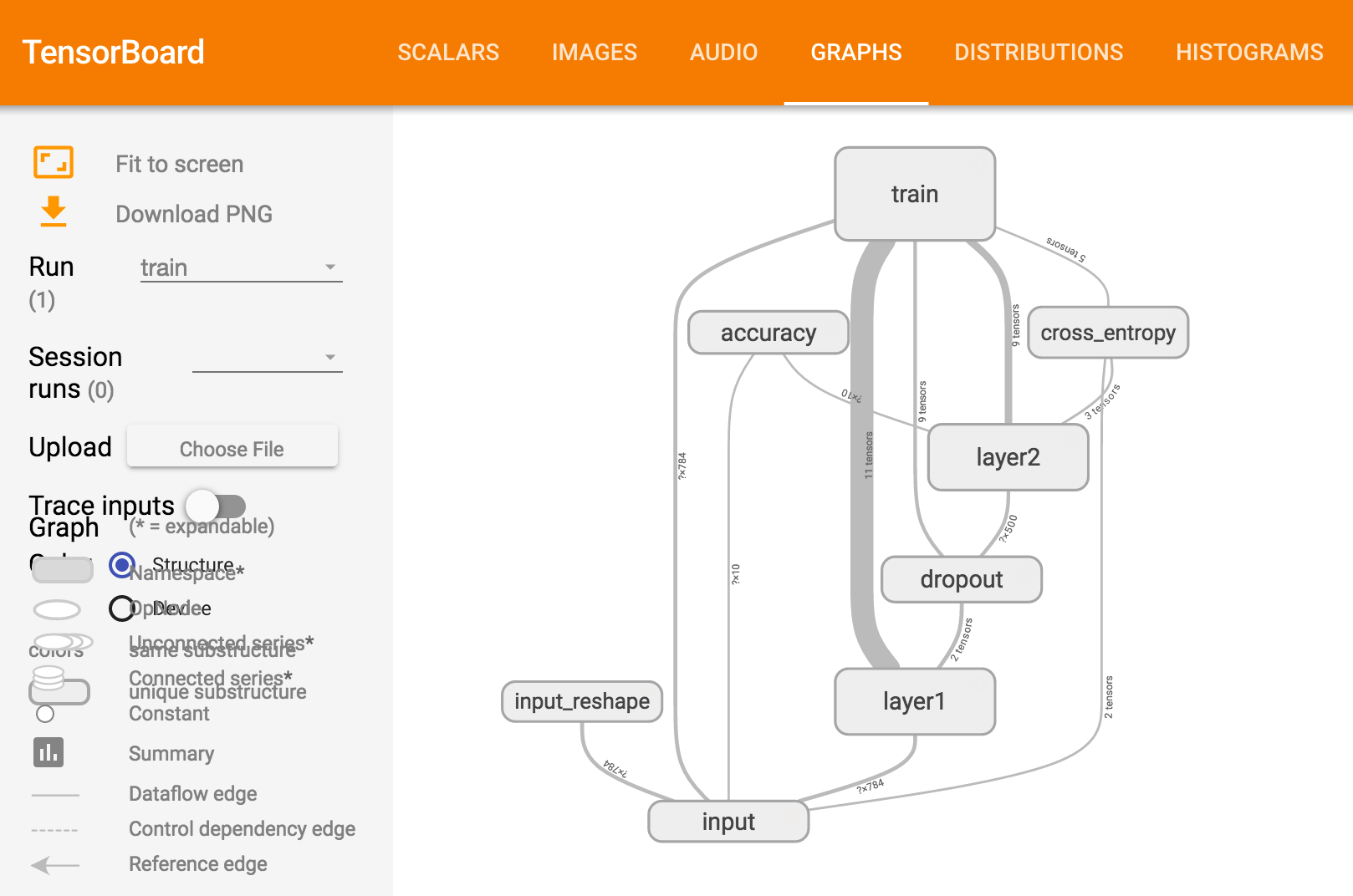
2.7 TensorBoard
TensorBoard 是tensorFlow 推出的可视化工具。
cd /Users/maoyaozong/Desktop/maoyaozong/cloudwood/tf
python book7.py
tensorboard --logdir=/Users/maoyaozong/Desktop/maoyaozong/cloudwood/tf
2.8 手写体数字问题MNIST
如何表示这些图片?
每一张图片包含28*28个像素点, 可以用一个数字数组来表示一张图片。
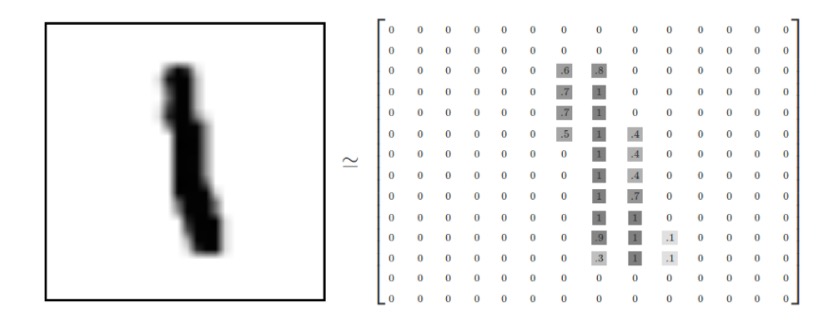
展开之后是28*28 = 784。
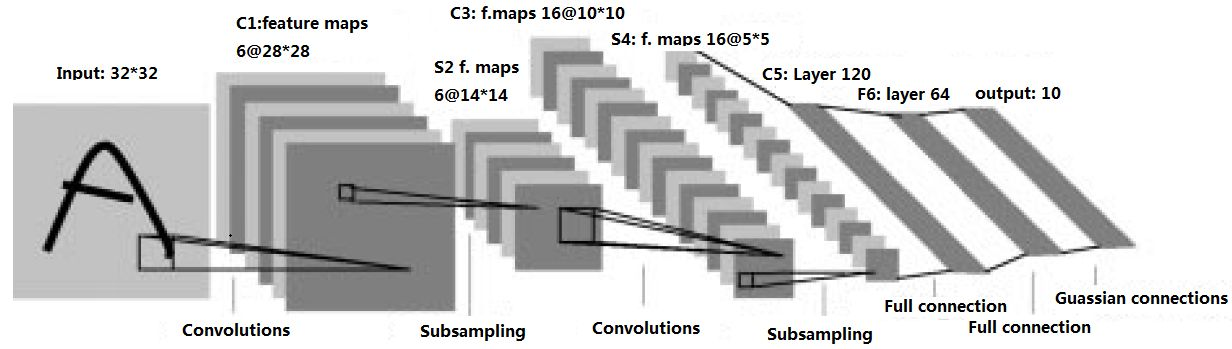
用LeNet 来试一下
1:// -*- coding: utf-8 -*-
2:import sys
3:reload(sys)
4:sys.setdefaultencoding("utf-8")
5:from tensorflow.contrib import learn
6:mnist = learn.datasets.load_dataset('mnist')
7:import tensorflow as tf
8:from numpy import *
9:
10:def trans_labels(labels):
11: yList = []
12: for j in range(len(labels)):
13: index = labels[j]
14: tmpList = []
15: for k in range(10):
16: tmpList.append(0)
17: tmpList[index] = 1
18: yList.append(tmpList)
19: yList = array(yList)
20: return yList
21:
22:sess = tf.InteractiveSession()
22://定义一个初始化权重
23:def weight_variable(shape):
24: initial = tf.truncated_normal(shape,stddev=0.1)
25: return tf.Variable(initial)
26://定义偏差
27:def bias_variable(shape):
28: initial = tf.constant(0.1 , shape=shape)
29: return tf.Variable(initial)
30://定义卷积
31:def conv2d(x,W):
32: return tf.nn.conv2d(x,W,strides=[1,1,1,1] , padding="SAME")
33://定义池化
34:def max_pool_2x2(x):
35: return tf.nn.max_pool(x , ksize=[1,2,2,1] , strides=[1,2,2,1] , padding="SAME")
36:
37:x = tf.placeholder(tf.float32 , [None , 784])
38:y_ =tf.placeholder(tf.float32 , [None , 10])
39:x_image = tf.reshape(x , [-1 , 28 , 28 , 1])
40:
41://定义第一个卷积
42:w_conv1 = weight_variable([5,5,1,32]) // 生成5*5 的权重矩阵,通道为1 , 卷集核数目为32
43:b_conv1 = bias_variable([32]) // 为每一种卷积核赋予一个偏差
44:h_conv1 = tf.nn.relu(conv2d(x_image , w_conv1) + b_conv1) //卷积运算后加上偏差,然后通过激活函数
45:h_pool1 = max_pool_2x2(h_conv1) //对卷积的结果进行池化
46://定义第二个卷积核
47:w_conv2 = weight_variable([5,5,32,64]) //第二个卷积核的尺寸和第一个一样 , 通道有32个,卷积核64个
48:b_conv2 = bias_variable([64])
49:h_conv2 = tf.nn.relu(conv2d(h_pool1 , w_conv2) + b_conv2) //对第二个隐藏层做卷积运算
50:h_pool2 = max_pool_2x2(h_conv2)
51://这时候的图片尺寸是7*7, 加上64个卷积核,一共有7*7*64个参数,3136
52:// 加上一个全连接的隐藏层, 隐藏层个数1024个
53:w_fc1 = weight_variable([7*7*64 , 1024])
54:b_fc1 = bias_variable([1024])
55:h_pool2_flat = tf.reshape(h_pool2 , [-1 , 7*7*64]) // 将原来的图片展开成为一维 , -1代表的含义是不用我们自己指定这一维的大小,函数会自动计算
56:h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat , w_fc1) + b_fc1) // 全连接
57:// 在训练的时候需要dropout
58:keep_prob = tf.placeholder(tf.float32)
59:h_fc1_drop = tf.nn.dropout(h_fc1 , keep_prob)
60:// 最后加一个输出softmax
61:w_fc2 = weight_variable([1024 ,10])
62:b_fc2 = bias_variable([10])
63:y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop , w_fc2) + b_fc2)
64:
65:cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y_conv) , reduction_indices=[1]))
66:train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
67:
68:tf.global_variables_initializer().run()
69:
70://进行训练
71:for i in range(20000):
72: batch_xs , batch_ys = mnist.train.next_batch(50)
73: batch_ys = trans_labels(batch_ys)
74: train_step.run({x:batch_xs , y_:batch_ys , keep_prob:0.5})
75: if i%100 == 0:
76: correct_prediction = tf.equal(tf.argmax(y_conv,1),tf.argmax(y_,1)) //得到值最大的那个下标
77: accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
78: print "the " , i , " iter :" , accuracy.eval({x:batch_xs , y_:batch_ys , keep_prob:1.0})
79://进行预测
80:correct_prediction = tf.equal(tf.argmax(y_conv,1),tf.argmax(y_,1))
81:accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
82:labelList = trans_labels(mnist.test.labels)
83:print "the final accuracy :"
84:print accuracy.eval({x:mnist.test.images,y_:labelList , keep_prob:1.0})
最后得到效果为99.2%
三、有意思的例子
风格转换
【每个人都是梵高】《A Neural Algorithm of Artistic Style 》

“绘画风格”是一个抽象定型的词语,它可能和图像的某种高阶统计量相关,但不同的绘画风格有不同的表示,对于一个没有具体定义风格的一般性问题,它很难用人工设计算法去完成。
卷积网络CNN可以通过多层卷积提取物体的抽象特征完成物体识别,这一点“提取抽象特性”的能力被作者借用来描述“风格”。经过多层CNN抽象之后的图片丢弃了像素级的特征,而保留了高级的绘画风格。
在文章里,作者使用了CNN作物体识别的VGG模型 ,定义了一个5层的CNN网络,梵高的星空在通过第一二三层的时候保留了一些原图的细节,但是在第四第五层的时候,就变成了“看起来是梵高星空的样子”这样的抽象特征:

这时候作者机智的想到了,如果把一张梵高一张其他照片同时都放到这个CNN网络里,经过合适的调整让第二张照片在第四五层接近梵高,而第一二三层保持和原来差不多,那就可以模仿梵高了!
学习风格并生成图像
于是让机器模仿绘画风格并生成图片成了一个优化问题:生成的图像要像原内容图,比如我给一张猫的图片最终还是要像猫;生成的图像要像是由风格图画的,比如我给了个梵高的图,我生成的猫的图片要看起来有梵高的风格。
也就是说要找到这样一个中间结果,它的内容表示(第一二三层CNN)接近于猫,它的风格的表示(第四第五层CNN)接近于梵高。
白噪声(white noise)是指功率谱密度在整个频域内均匀分布的噪声。
作者用一个白噪声图片通过梯度下降生成一个接近内容图的图片,以及另一个白噪声图片生成一个接近绘画图风格的图片。
定义了这两个图的损失函数并加权平均当作优化目标函数 , 通过梯度下降(SGD)完成收敛找到这样一个内容和风格都搭配中间结果。
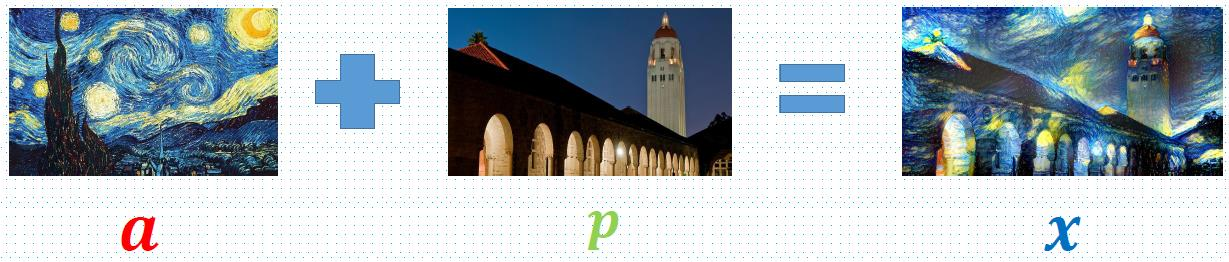
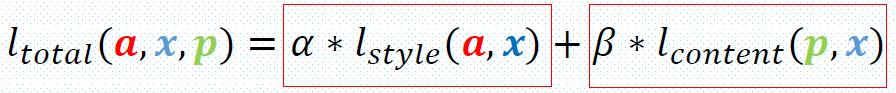
定义了两个loss,分别表示 结果图x 和 风格图a 的样式上的loss , 以及x和内容图p的内容上的loss 。
不同的 α/β的比例指更注重style还是更强调content。
假设内容P 和 结果X 在CNN中的相应分别为P 和 F , 计算在内容上的损失。
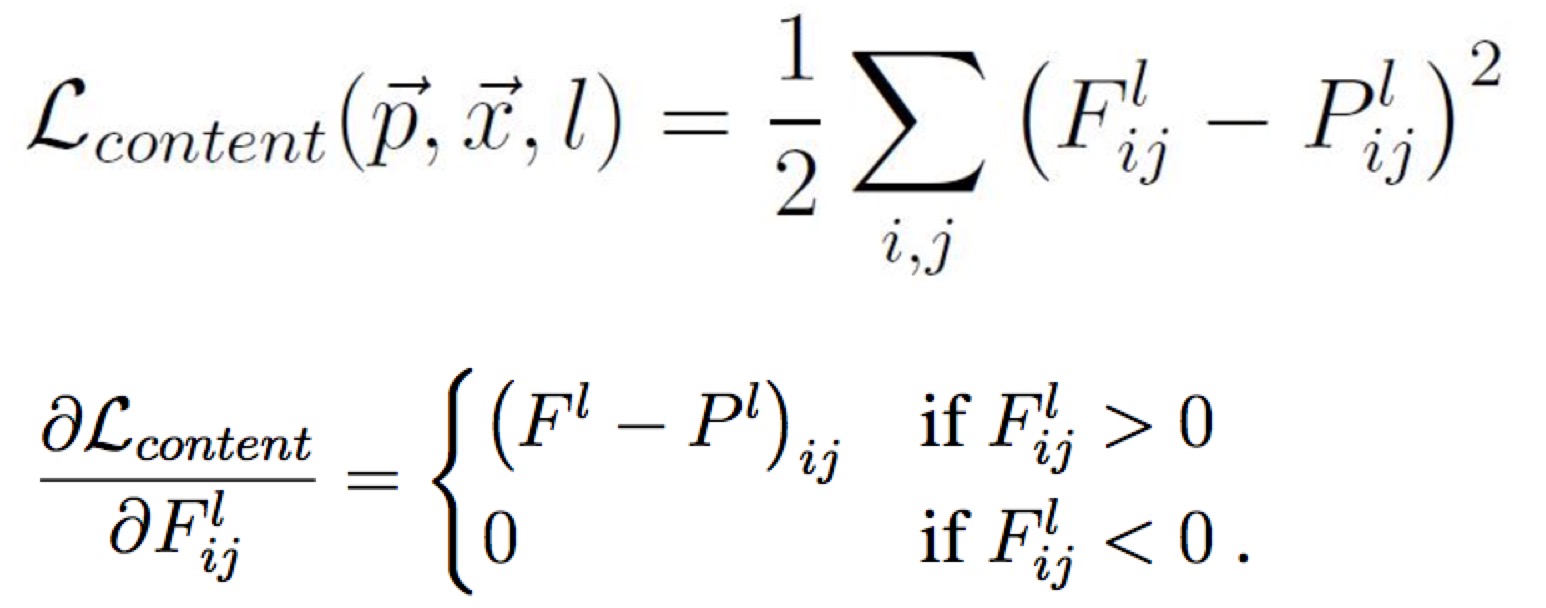
风格定义公式,CNN同一层不同filter响应的互相关,通过描述互相关来表示style。
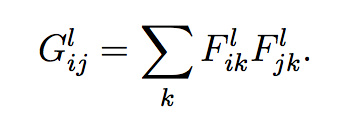
每一层的损失:
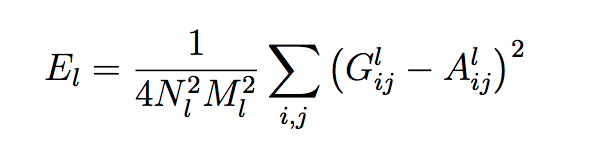
优化方向:
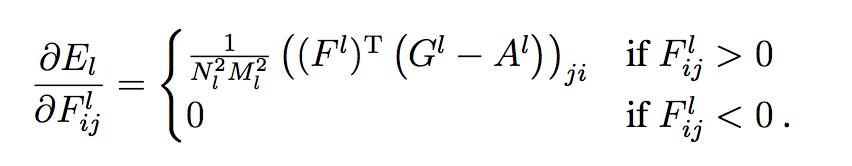
迭代最小化:
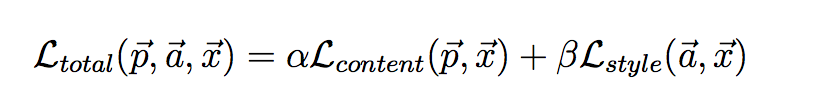
实验效果
1、迭代300轮与600轮差异

2、
