PS,本文是一个针对非前端程序员的科普贴,吸纳了很多现有文章的内容。
一句话
前端是是一种技术问题较少、工程问题较多的软件开发领域。
——张云龙
换言之:前端工程师就是一个高级技工。
资源管理的历史
胖总化身农名工,开始穿越。
第一阶段
上世纪末期和本20世纪开始的几年,作为农民工的胖总,只要知道怎么盖房子就可以了,盖房子其实很简单,拢共分三步:
- 打地基:会好HTML
- 搞装修:会写CSS
- 综合布线、集中采暖、防汛工程等功能性劳动:会写JS
尼玛能把这三个东西黏在一起往服务器上一堆就ok了,哪儿管那么多!
第二阶段
web2.0来了,05年开始,什么校内网、占座网、my space都来了。他们都嚷嚷着要建楼,而且把工程都包给了胖总。
胖总惆怅了,原因有2。
一是这些甲方太tmd难伺候了,事儿真多,功能特别复杂。
二是这些楼访问量太大了,按照之前盖房子的方式,人一多就得倒。
咋办?
这时候就要有资源管理的意识了。
咋管理?
- CDN,其实这玩意儿98年就出来了,但是胖总现在才开始正儿八经地用。他很好用,就是给甲方建好多楼,全国各地都是,防止甲方的客户全跑总部来,把总部给挤垮了。
- 资源合并加载,这太好理解了。之前盖房子都是一块砖一块砖地盖,现在尼玛用了钢筋混泥土,直接按照施工方案,直接把整体的骨架浇筑完成,既提高了效率,也加强了建筑物的强度。
- 合并的目的一:减少HTTP请求数(但是有节制的合并,不能太过激进,要在请求书和请求量之间寻找平衡点)。
- 合并的亩地二:基于合并进行文件压缩(再附加gzip),包括变量替换,代码混淆等等。
- 不光代码可以合并,图片也可以合并,css sprite!

第三阶段
模块化开发来了!!!!
我艹,这下胖总牛逼了。
还记得亨利福特开创的流水线生产么?胖总发现,尼玛管理一个个人人都是多面手的包工队成本太高。你,你,还有你,你们仨儿以后只负责打地基;你,你,还有你,你们仨儿以后只负责封顶;你,你,还有你,你们仨儿以后只负责浇筑。
胖总搞突然发现,原来让大家各司其职,好处真大!
专业的人做专业的事情,而且他们做出来的东西还可以被别人复用,太tmd爽了。
模块化开发其实会有很多理解方式,在前端工程领域包括但不限于这么几个理解方式:
- 模板模块化:头部、底部、列表、用户信息。。。。
- 脚本模块化:实现同一种功能的脚本放一起。。。。
- 样式模块化:
- 大家知道通用的样式放在一起了
- OOCSS的诞生,大家发现样式都能tmd面向对象了
- LESS,SASS,SCSS这些样式编译工具的但是,我艹,可以随意定义变量和mixin,还能相互依赖了!
有了模块化,就得有加载器啊!
这就好比,有人给你在别的地方把楼顶先做好了,你得有吊车把楼顶吊过来啊!
所以加载器就是基于模块间的依赖关系,来进行依赖加载的东东。
10到12年,这东西特别火,有AMD的requireJS加载器,还有CMD的SeaJS加载器。。。。这里就不讨论什么是前置依赖,什么是运行时依赖,反正你就记住,加载器就是让模块之间有依赖关系时,找到依赖的模块并加载之!!!
但是,又有一个问题来了!!!
这尼玛如果加载依赖的JS和CSS是在运行时加载,那么岂不是要发好多HTTP请求?那用户看到的页面应该就和吃了屎的幻灯片一样,一部分一部分出来。这楼房还你能住?
所以,第二阶段的合并思想当然要引入到模块化开发中。
这时候,胖总发现,我艹,太牛逼了。有了模块化开发和加载器,做合并再也不用无脑合并了,而是可以根据模块之间的依赖关系合并!!!!
牛逼了,牛逼了,牛逼大发了!
但是,胖总先hold住第三阶段的激情澎湃,我们先看下第四阶段是什么?
第四阶段
组件化开发!!!
听起来高大上的名字,其实本质上就是爸之前的粪便基于模板、脚本和样式的模块化,变成了基于“模板+脚本+样式”的一揽子的模块化开发!!!!
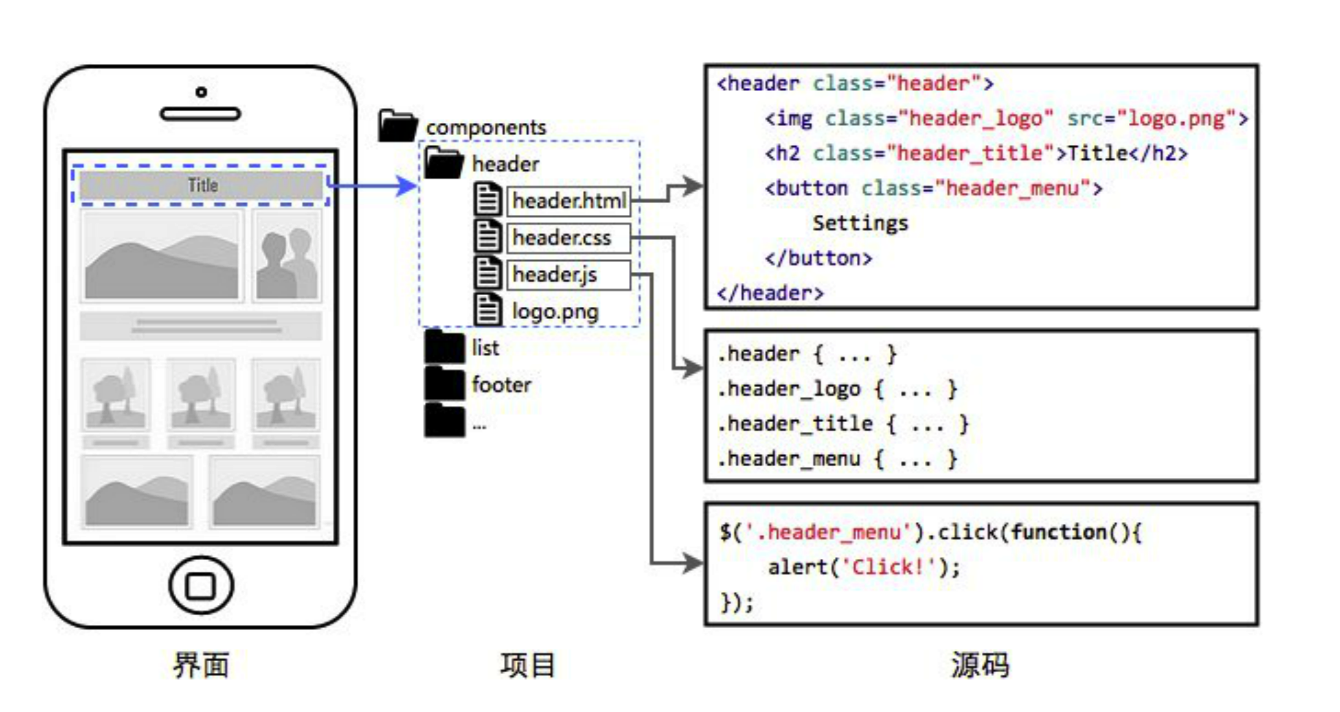
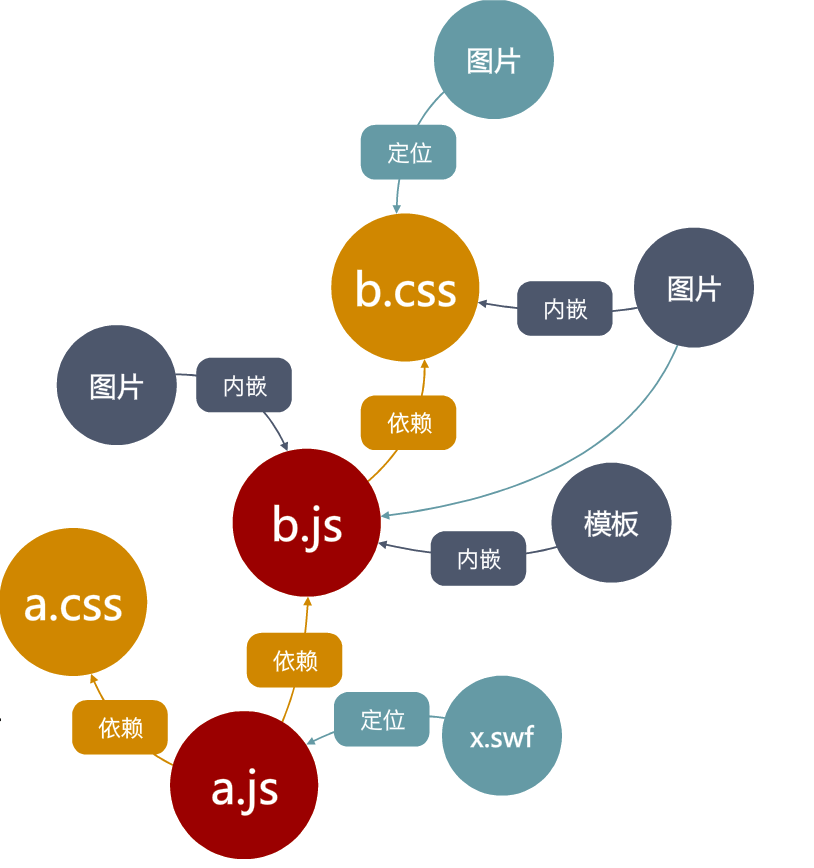
看起来没什么,但是我们来分析一下背后可能的依赖关系:
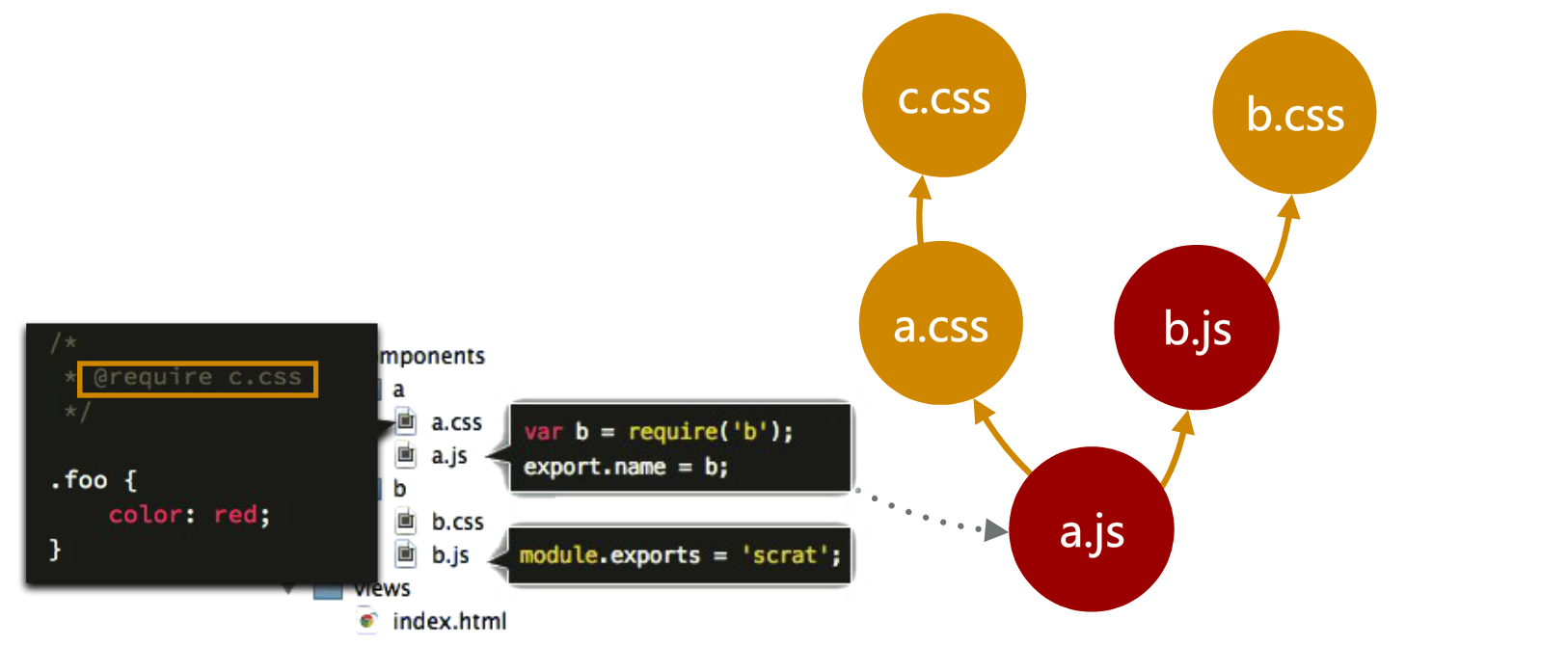
那么,怎么描述这种关系呢,那就需要资源表
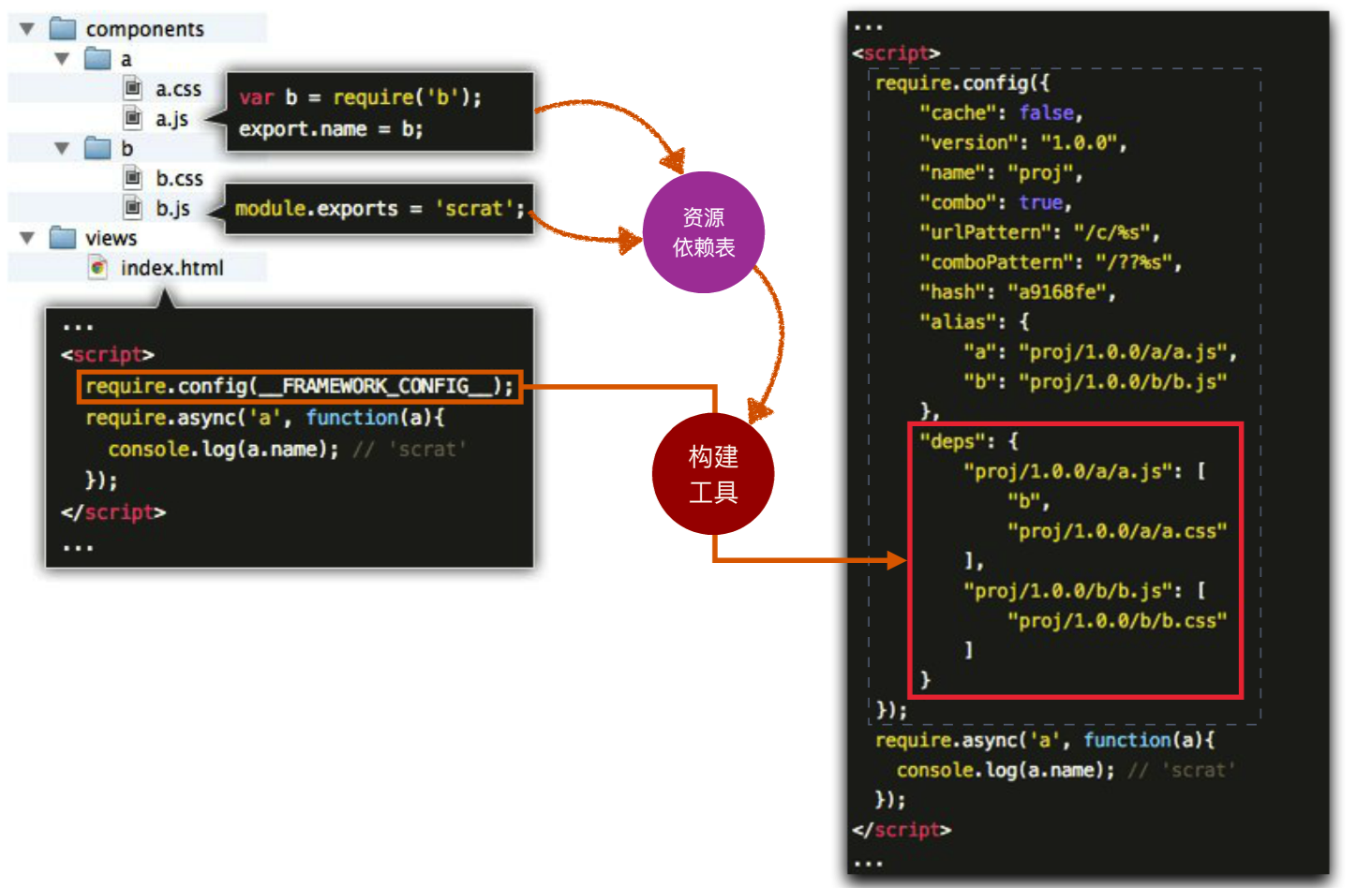
利用服务端的技术,我们可以在运行时进行资源合并,并且用CDN缓存合并响应:
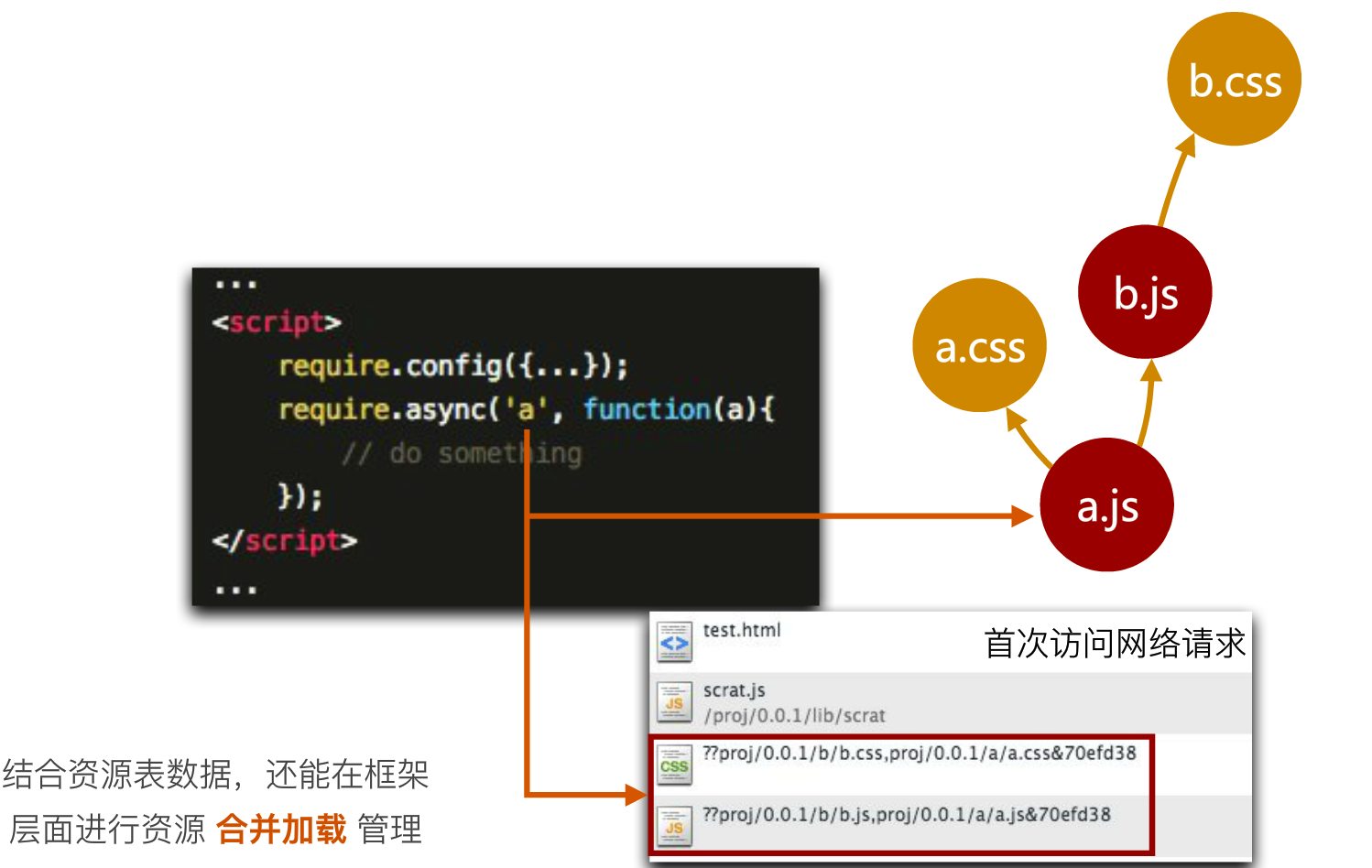
以上只是针对脚本和样式的合并加载方案,对于模板,也可以将其内嵌到脚本中:

不光是模板,零碎的图片也可以以base64编码的形式嵌入到样式文件中。
综上:通过内嵌、依赖和定位管理所有前端资源,通过资源加载框架读取资源表,实现资源加载的程序化控制:
这就够了么?
显然不够!
因为不够快!
浏览器渲染的基本流程:
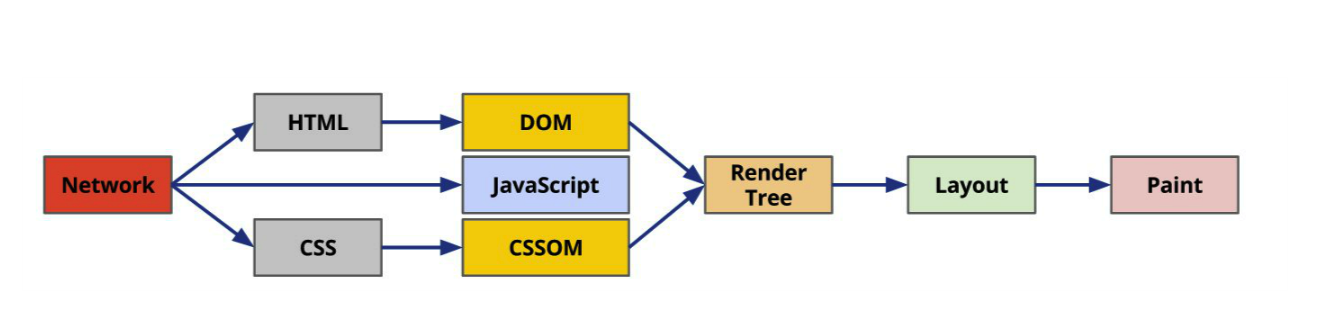
- HTML解析,构建DOM树;
- CSS解析,构建CSSOM树;
- 融合为Render树;
- 布局计算;
- 屏幕绘制。
key点:尽快让浏览器建立DOM和CSSOM树以便渲染页面
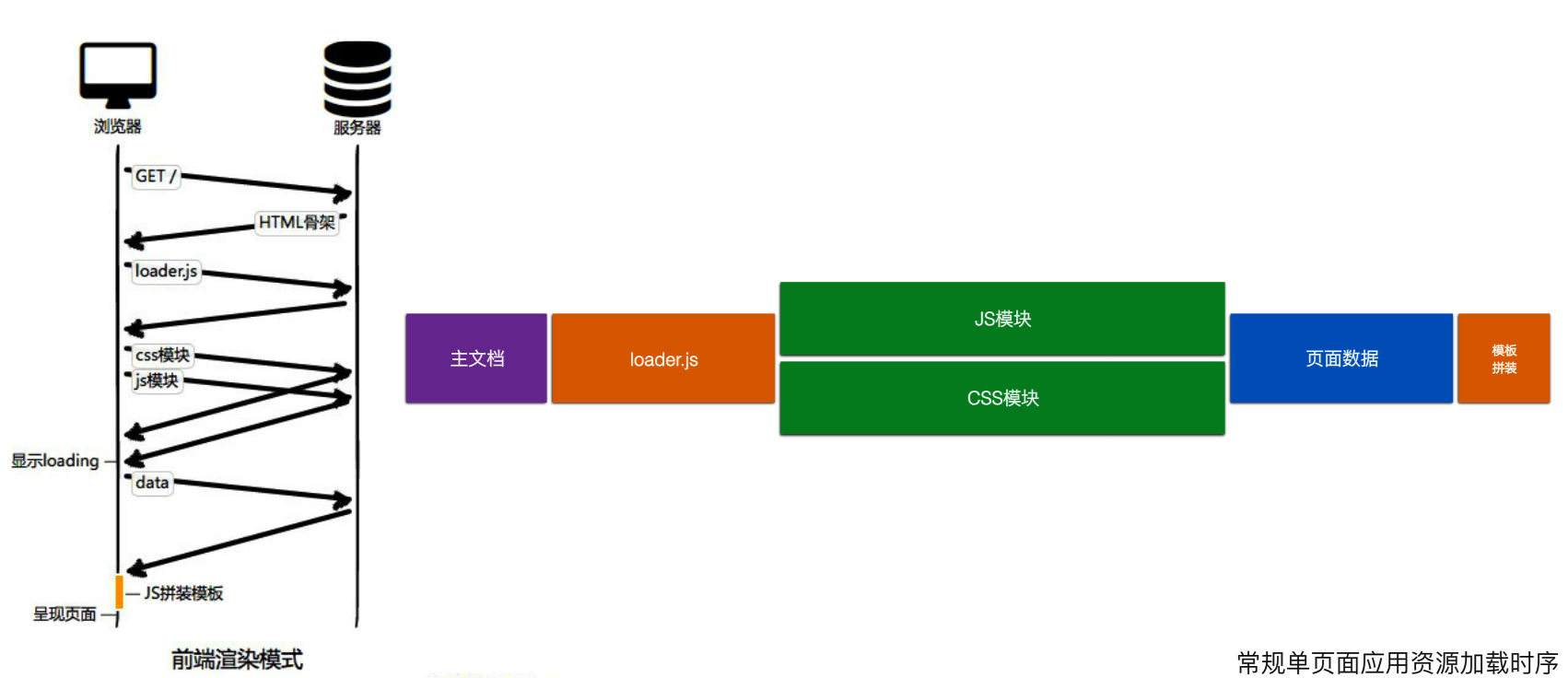
RTT(Round-Trip Time): 往返时延——性能毒瘤!
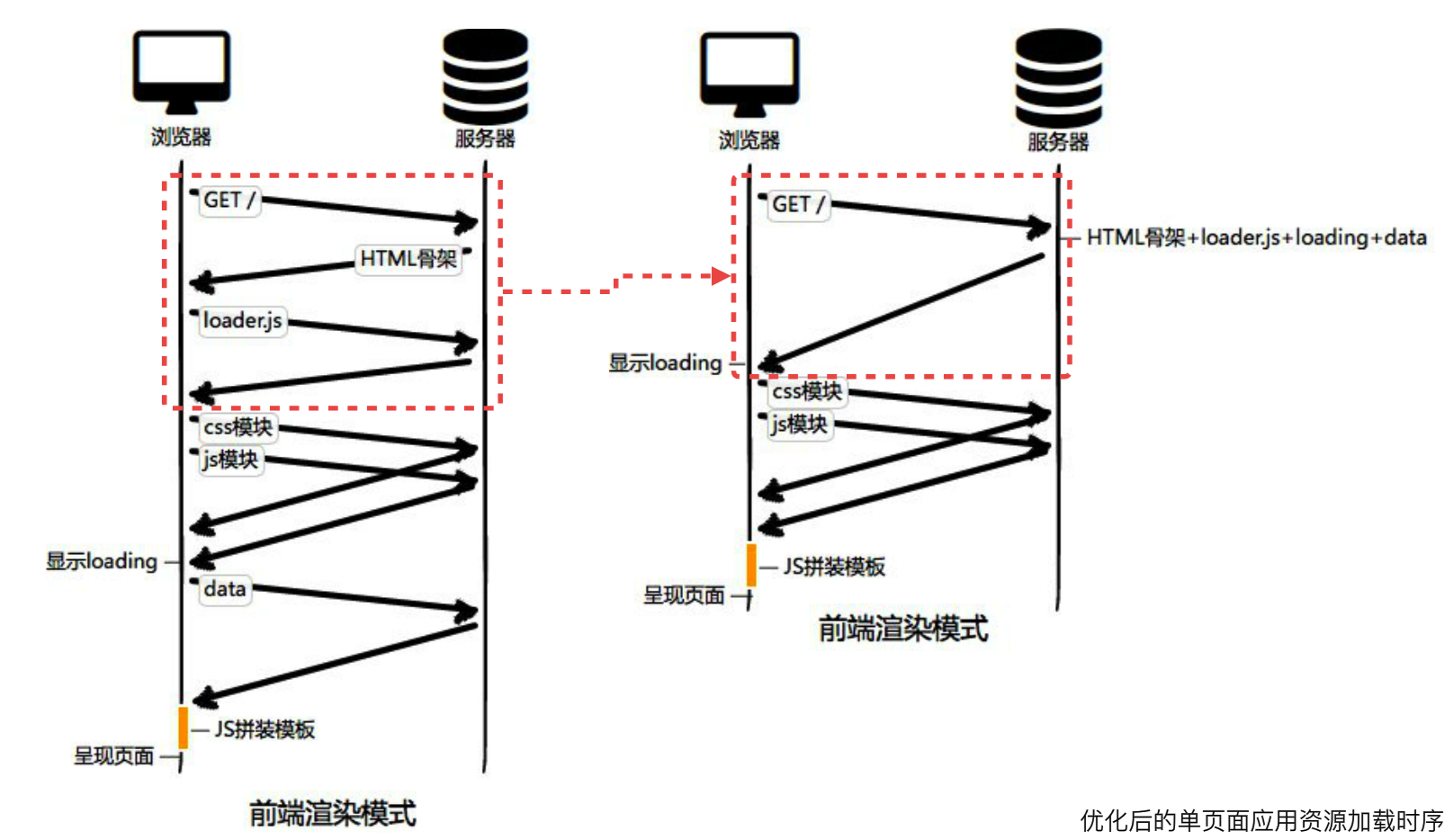
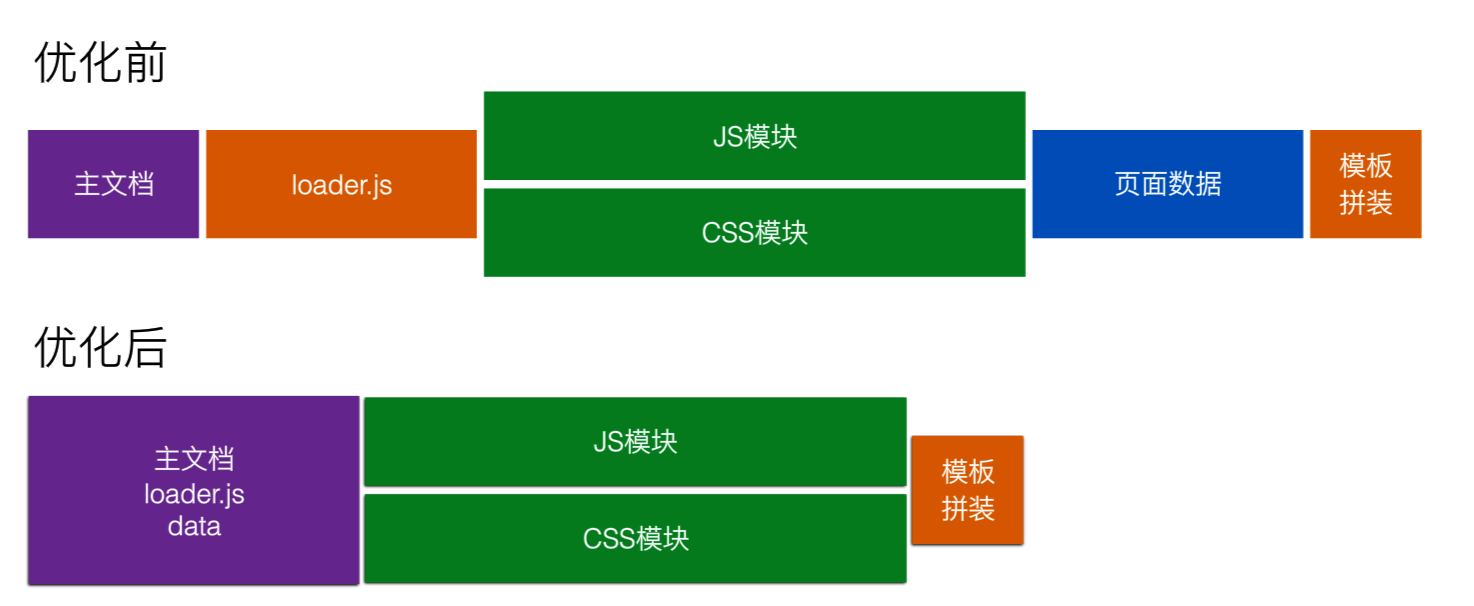
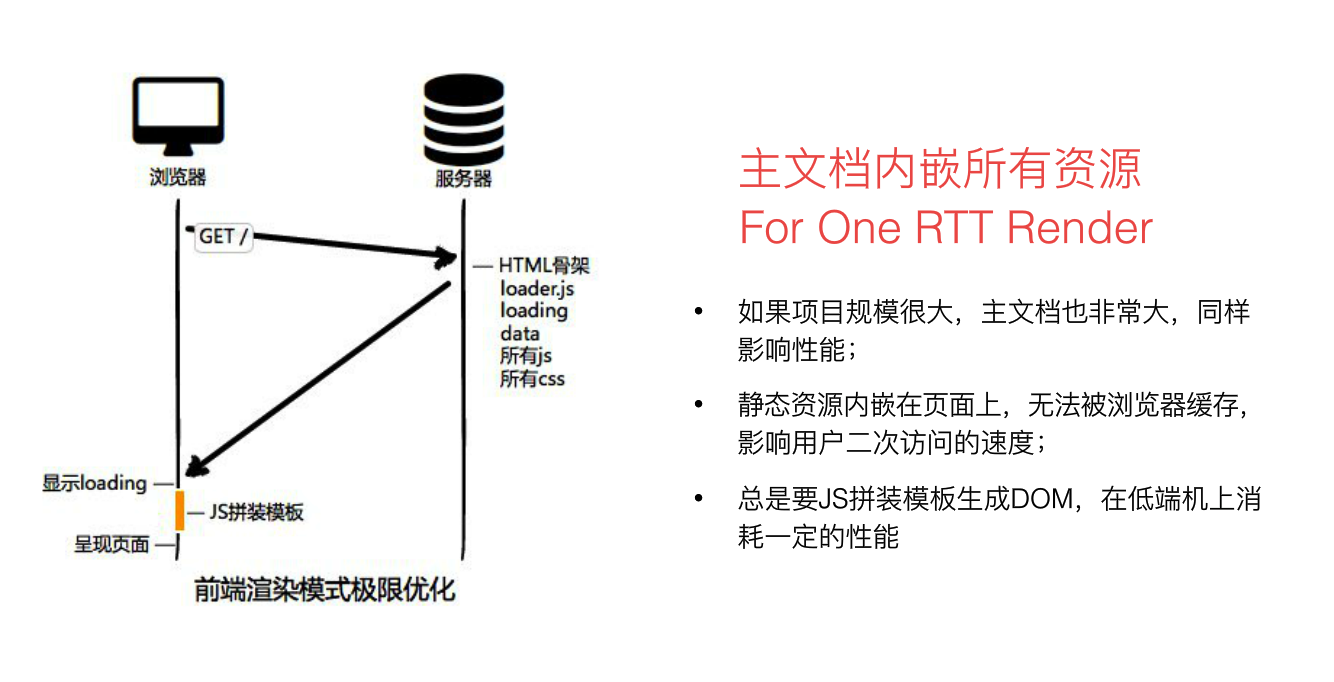
前端渲染的极限方案:
前端按需加载!
前端先加载首屏资源(首屏一个RTT),然后再获取其他屏的资源渲染。
后端渲染
上面讲了半天,其实都是在死磕前端渲染,虽然前端渲染具备较强的控制力,但是性能堪忧。
服务端(首屏)直出!
- 组件化/模块化开发;
- 在服务端引用组件们;
- 按需找到组件依赖的JS和CSS;
- 合并JS和CSS;
- 将合并好的组件的CSS和JS内嵌到首屏输出的HTML里(CSS在前,JS在后);
- 收集页面内的零碎脚本到最后。

facebook三驾马车
其实这是一套非常老的技术,诞生于10年,可以配合前面所述的组件服务端直出一起使用:
bigpipe、quickling、pagecache!!!
bigpipe
上面讲了半天首屏,尼玛其实首屏的定义时PM给出来的,不一定在正中间的就是首屏。
所谓首屏,就是PM认为最重要的页面部分。
看下facebook(这图尼玛有点儿老):
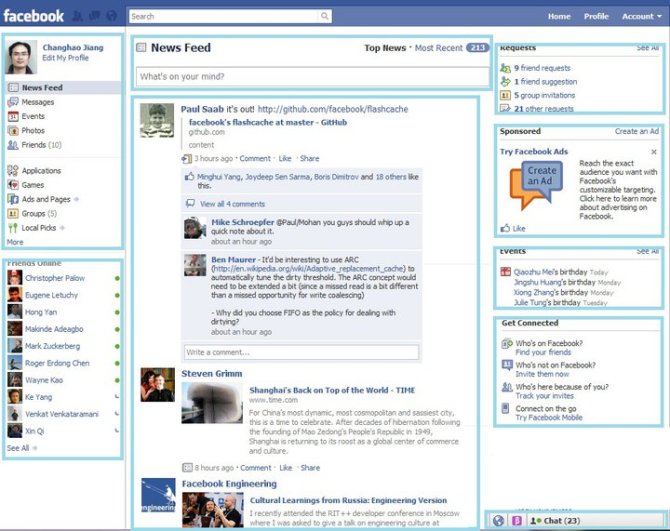
你会怎么实现?
扣div + ajax?
no!
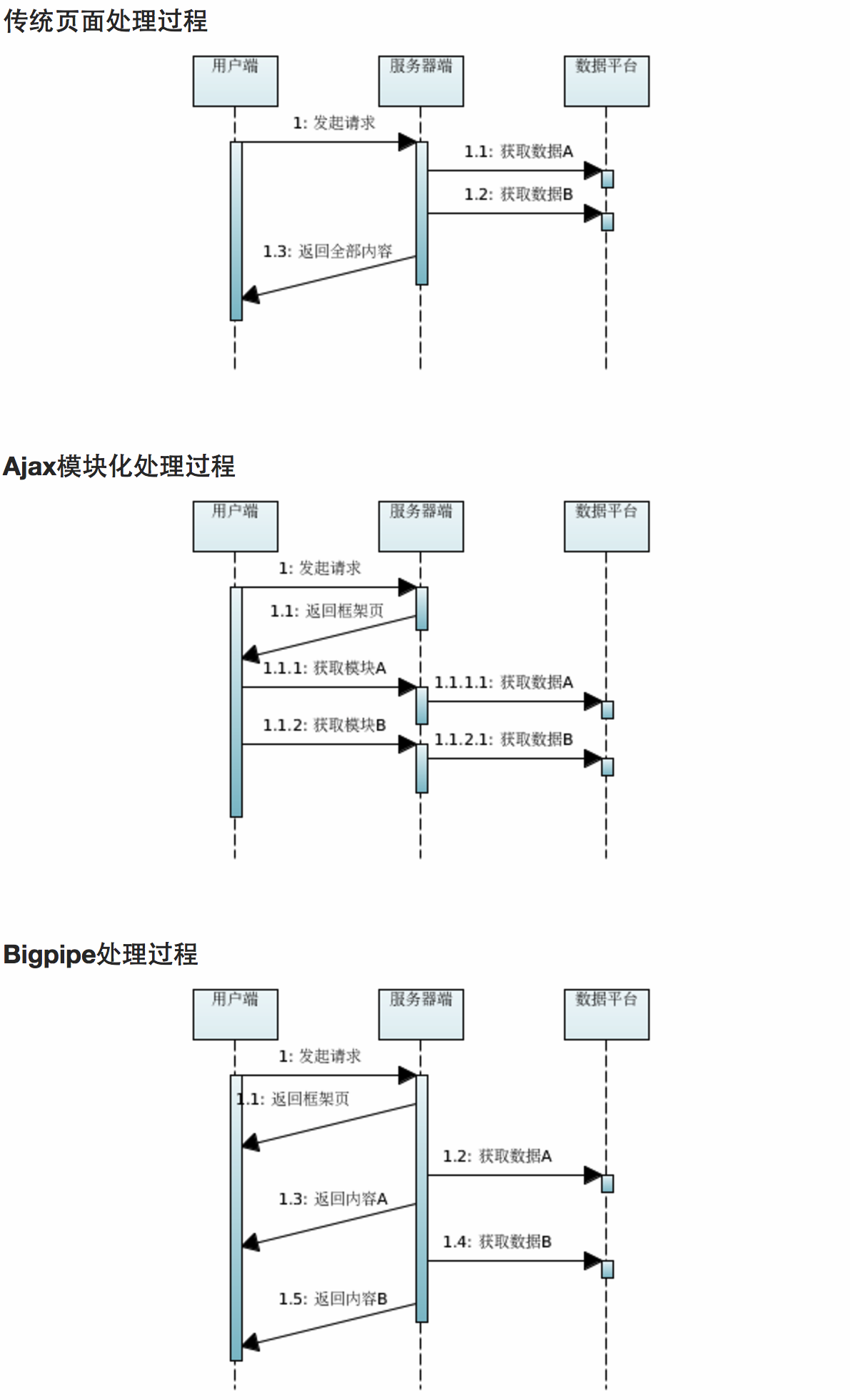
可以用一个叫做bigpipe的东西,其实这是一个技术合集:
- 定义页面区域(pagelets),并确定屏幕次序(根据重要度);
- 服务端chunk输出;
- 前端有一套触发式的加载框架。
quickling
尼玛其实就是把传统的html请求变为ajax,一次性搞回来模板+js+css,然后热替换现有的内容;
pagecache
其实就是保存下页面,切换回来的时候直接从缓存(其实就是浏览器内存)中读取,比如在tb切换的时候。
缓存跟前端部署的那一腿
相信搞前端的没人不知道200、200 from cache和304都代表什么:
- 200: 从服务端请求资源成功
- 200 from cahce:直接从浏览器里拿
- 304:服务端告诉你,别废话,直接用上次的
看起来200 from cache更牛逼一些,强制浏览器使用本地缓存(cache-control/expires),不要和服务器通信。好了,请求方面的优化已经达到变态级别,那问题来了:你都不让浏览器发资源请求了,这缓存咋更新?
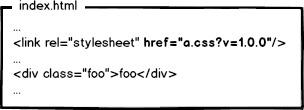
但是,问题来了:
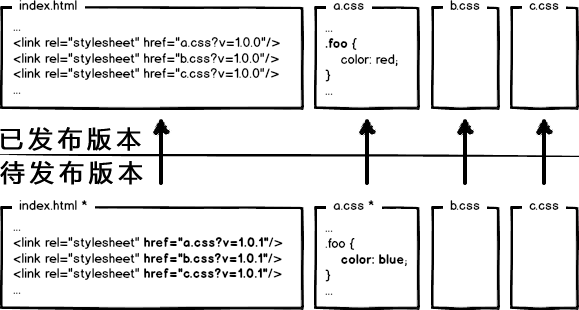
每次全都更新这岂不崩溃?所以,我们不难发现,要解决这种问题,必须让url的修改与文件内容关联,也就是说,只有文件内容变化,才会导致相应url的变更,从而实现文件级别的精确缓存控制。
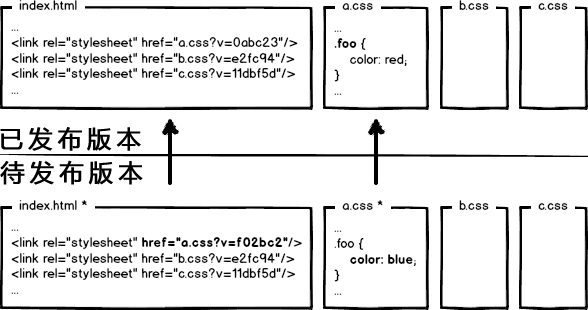
完事儿了?no!考虑如下这种情况:
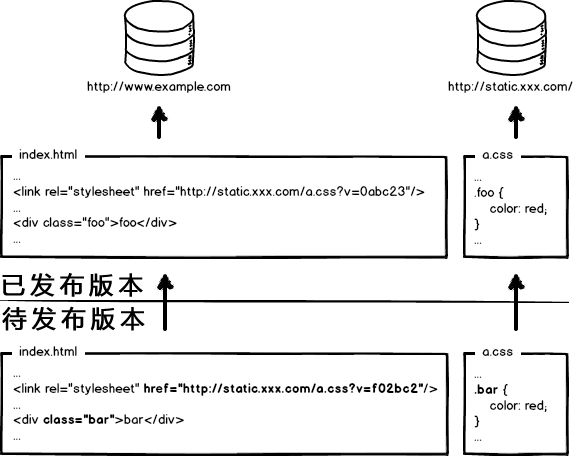
到底是先上线静态资源还是页面?
- 先部署页面,再部署资源:在二者部署的时间间隔内,如果有用户访问页面,就会在新的页面结构中加载旧的资源,并且把这个旧版本的资源当做新版本缓存起来,其结果就是:用户访问到了一个样式错乱的页面,除非手动刷新,否则在资源缓存过期之前,页面会一直执行错误。
- 先部署资源,再部署页面:在部署时间间隔之内,有旧版本资源本地缓存的用户访问网站,由于请求的页面是旧版本的,资源引用没有改变,浏览器将直接使用本地缓存,这种情况下页面展现正常;但没有本地缓存或者缓存过期的用户访问网站,就会出现旧版本页面加载新版本资源的情况,导致页面执行错误,但当页面完成部署,这部分用户再次访问页面又会恢复正常了。
解决方法:覆盖式发布。
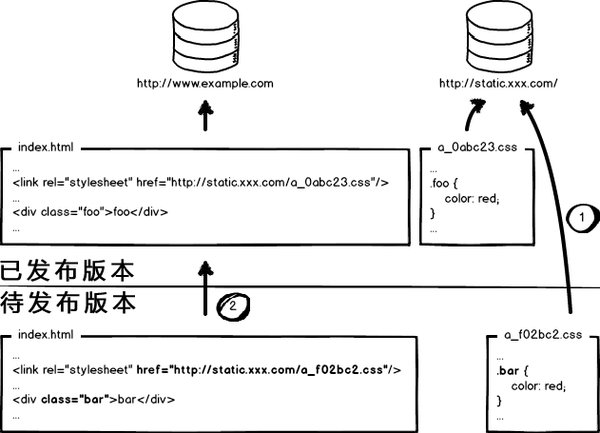
看上图,用文件的摘要信息来对资源文件进行重命名,把摘要信息放到资源文件发布路径中,这样,内容有修改的资源就变成了一个新的文件发布到线上,不会覆盖已有的资源文件。上线过程中,先全量部署静态资源,再灰度部署页面,整个问题就比较完美的解决了。
所以,大公司的静态资源优化方案,基本上要实现这么几个东西:
- 配置超长时间的本地缓存 —— 节省带宽,提高性能
- 采用内容摘要作为缓存更新依据 —— 精确的缓存控制
- 静态资源CDN部署 —— 优化网络请求
- 更资源发布路径实现非覆盖式发布 —— 平滑升级
全套做下来,就是相对比较完整的静态资源缓存控制方案了,而且,还要注意的是,静态资源的缓存控制要求在前端所有静态资源加载的位置都要做这样的处理。是的,所有!什么js、css自不必说,还要包括js、css文件中引用的资源路径,由于涉及到摘要信息,引用资源的摘要信息也会引起引用文件本身的内容改变,从而形成级联的摘要变化,大概示意图就是:
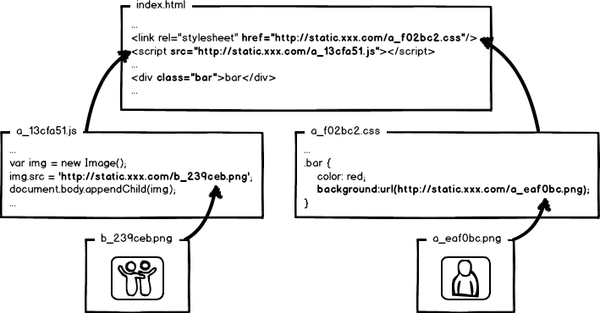
工具化
以上提到的静态资源依赖管理、内嵌以及定位功能,还有为了覆盖式发布进行的文件名替换,明显不能通过纯手工的方式去做。
这时候就需要引入工具化:
- 构建工具:构建工具的目的是让资源的依赖合并嵌入变得自动化,一行命令(甚至watch)就能产出最终的结果,而且还能解决资源相对地址和绝对地址切换带来的定位(CDN替换)问题。
- 集成工具:构建工具只是负责执行一次或者一批人物,将这些任务的上下游一起串联(包括单元测试、测试环境部署)等放在一起,就需要类似jekins和travis ci之类的东东。
- 部署工具:当然,集成工具理论上包括部署工具。但是单拎出来说的目的是,这东西主要解决的是线上线下环境切换(环境变量、相对地址、配置文件读取方式等)问题。
- 运行时工具:比如之前百度的在线智能打包(根据页面流量、负载等,合并最长访问的资源)等工具。
这些工具的出现,都是为了让模块化开发、组件开发变得更快捷。
当然,这东西迭代太快了。
- 从任务流的方式来看,有基于文件的grunt和基于stream的gulp和fis啊。。。
- 有专攻维度不同的,比如webpack专业盯着依赖打包,gulp提供任务组合,fis提供一揽子(包括前后端业务框架)解决方案。
总之,工具让生活更美好。
未来?
HTML5 offline app
坑爹的manifest!
简言之就是把页面以及页面里的静态资源都存储在浏览器里,后续直接从本地度,就算断网都能访问。
但是兼容性实在是呵呵,有的浏览器尼玛一旦cache,只能靠404清除。
HTTP 2.0
这个之前有讲过,其实,在HTTP2.0时代,之前的那些狗屁问题都不是问题了。
- 什么加载器,浏览器端systemjs直接一次性load出来。
- 图片加载……呵呵
- quickling?呵呵
都尼玛呵呵了。
综述
仅仅是一个前端资源加载,身为农民工的胖总就已经心力憔悴了。放眼未来,工程化的问题根本不需要经验,可能一个新的技术,之前你的所有积累都88。
所以,怎么保持自己不被淘汰:
- 学学学!
- 看思想,看原理,不要单单学API,学API一毛钱用都没有,那就真的是民工了。
完